How
Japanese Classifier is Represented in the Brain:
Semantics or Syntax?
Mutsumi Imai Faculty of Environment and Information Studies, Keio University
Mamiko Arata Graduate school of Media and Governance, Keio University
Junko Kanero Keio Research Institut, Keio University
Henny Yueng UBC Canada
Guillaume Thierry Bangor University
Hua Shu Beijing Normal University
Abstract By means of ERP recording, the present study investigates whether count/mass nouns are grammatically distinguished by count/mass classifiers as proposed by Chen & Sybesma (1999). Broadly distributed N400 was evoked for mismatched pairs of nouns and classifiers. The violation across count/mass categories (e.g. a count noun with a mass classifier) did not show any distinctive signature indicating syntactic processing, and elicited the same N400 effect as that of the within-category violation (e.g. a count noun with a count classifier). The results suggest that classifiers are primarily processed on semantic bases and do not draw the count/mass distinction.
1.
Introduction
1.1.
Grammatical Classification of Nouns
According to Quine (1969), young children do not master the meanings of objects or substances until they learn the syntax of quantification. In English, all nouns belong to either count-noun category or mass-noun category, and the differentiation between objects and substances is clearly and grammatically drawn by count/mass distinction. For instance, while any object names can be pluralized (e.g. cups, apples, pencils), pluralizing substance names is grammatically wrong (e.g. waters*, butters*). Another example would be determiners such as “a” or “an”, which can be only accompanied by object words. English explicitly draws count/mass distinction, and it is crucial for English speakers to pay attention to whether the topic of conversation is an object or substance.
The distinction between objects and substances are essential for the notion of identity or sameness. When we say that two objects are “identical” or “the same,” we are referring to them in their entirety. On the other hand, the sameness of a substance is determined on the basis of the sameness of its material constituent. (Quine, 1969; Imai & Mazuka, 2003). For example, the words “water” and “cup” are both basic words, but fundamentally different in their ontologies. While water would always be water regardless of how its shape changes by the container or how big/small amount of water there is, pieces of a broken cup could never be considered as a cup.
1.2.
Grammatical Gender
Another common type of noun classification is grammatical gender, which is commonly known to be found in European languages such as French, German, or Spanish. In this system, all nouns were categorized into gender categories such as masculine nouns and feminine nouns. Speakers of these languages have to be aware of the gender of each noun.
1.3.
Numeral Classifier System
In Japanese, numerical classifiers must be attached to a noun whenever the quantity is specified. We could say that the status of numeral classifiers is somewhat similar to quantifiers in English, such as a piece of or a portion of. The important difference between English quantifiers and numeral classifiers is that English quantifiers are used only for quantifying mass nouns, while the Japanese grammar demands numerical classifiers for all nouns. From this characteristic, some linguists and philosophers claim that all nouns are treated as mass nouns in classifier languages (Lucy, 1994; Chierchia, 1998)
Classifiers categorize entities in the world like nouns, but in a very different way. While the noun lexicon is organized by taxonomic relations, the classifier lexicon is organized around semantic features such as animacy, shape, dimensionality, size, functionality, and flexibility. Categories made by classifiers often crosscut taxonomic categories. For example, nouns classified with hon, a Japanese classifier for long, thin things including pens, baseball bats, home-runs, bananas, carrots, ropes, necklaces, wires, and telephone calls (Lakoff, 1987). In the Japanese classifier system, animacy is the most crucial among the criteria of the classification. Classifiers for animated words can never be used for non-animated words and vice versa. In other words, a very clear boundary exists between animated and non-animated categories in the Japanese classifier system.
1.4.
Ontological Distinction of Objects and Substance in Numeral Classifier System
There have been two opposing views regarding the count/mass distinction in classifier languages. Chierchia (1998) has argued that there is no grammatical count/mass distinction in classifier languages, and everything is treated as a mass noun. However, some linguists proposed that classifier languages grammatically make the count/mass distinction by classifiers (Chen & Sybesma, 1999; Mizuguchi, 2004). They have claimed that classifiers are categorized into count classifiers and mass classifiers, which used primarily for count nouns and mass nouns respectively. Thus, speakers of classifier languages can learn the ontological difference of objects and substances through using two types of classifiers. In other words, they suggested that speakers of languages with classifier system have grammatical count/mass distinction by classifiers.
Imai & Gentner (1997) have tested English- and Japanese-speaking children to see how they extend the meanings of novel words. They found that children in both languages showed differentiation between simple objects and substances as early as 2 years of age, suggesting the existence of the universal ontological distinction. However, American children, in contrast to Japanese children, had tendency to generalize novel words for simple entities based on their shapes when its count/mass syntactic status is not explicitly given. Using the same sets of stimuli, Imai & Mazuka (2003) have also suggested that English-speaking adults assume the novel nouns presented in the ambiguous syntactic frame to be count nouns.
Though a cross-linguistic difference between a language with count/mass syntax (English) and a language with the numeral classifier system (Japanese) were found to a certain extent, it is still unclear if the difference was caused by the difference in the lexical level or the grammatical level. In order to further investigate the notion, the examination of underlying brain activities was necessary.
1.5.
ERPs of Word Processing
N400 is one of the most well researched components. It was first discovered in 1980 by Kutas and Hillyard, and they have reported negativity was observed to a word at the end of a sentence which is mismatch to the context (e.g. He took a sip from the transmitter.) In other words, N400 is elicited when a subject is exposed to unexpected words. It appears after around 400ms from the onset of mismatch words and peaks around the center of the scalp. Friederici has argued that N400 reflects semantic integration at the lexical level (2002).
In contrast, LAN(Left Anterior Negativity) is distributed to left anterior region but usually observed at the similar time window. LAN is said to be reflecting the violation of grammar such as tense, number, and gender.
Another left lateralized negativity which is possibly related to our study is Early Left Anterior Negativity or E-LAN. Its time window is earlier than LAN and is around 150-300ms after the stimuli onset. E-LAN is also a component related to syntactic violation.
Previous research has suggested that the neural process of the count/mass distinction in English is primarily syntactic based. Steinhauer et al.(2001) have run an ERP study using count nouns and mass nouns as stimuli. Their finding is that independent of the violation, count nouns elicited left-lateralized negativity. They concluded the negativity is LAN and count/mass distinction is syntactically processed. Moreover, in the study of Bisiacchi et al.(2005), left anterior negativity around 150ms after word onset in categorization task of count nouns and mass nouns. This ERP component could be considered as E-LAN. Thus, there is a general agreement that count/mass distinction in English relies on syntactic process instead of reflecting semantic process of word meaning.
In ERP studies of the gender mismatch, several literatures claim that processing of grammatical gender is primarily syntax based. Munte et al. reported that LAN effects were observed for the disagreement of articles and nouns in German (1993). Barber et al. (2005) have also observed LAN effects for the gender mismatch of article-noun pairs.
Compared to grammatical gender systems, relatively fewer ERP investigations were done for the processing of numeral classifiers. In their ERP study on L2 language acquisition of Japanese, Mueller et al. (2005) have observed left lateralized negativity for the violation of classifiers in sentences. They have concluded that the observed negativity was LAN, thus classifiers are syntactically processed. In contrast, Sakai et al. (2004) argue that the processing of classifiers is primarily semantic-based because they have observed center-peaked N400-like component in their study using word-classifier pairs. Tsai (2009) has also found N400-like component very similar to what Sakai et al. in his study of Chinese classifiers.
1.6.
Present research
If count/mass nouns are grammatically distinguished by count/mass classifiers as suggested by Chen & Sybesma, (1999), the violation across count/mass categories (count nouns with mass classifiers or mass nouns with count classifiers) should elicit an ERP signature of syntactic mismatch when compared to violation within a count/mass category (count nouns with mismatched count classifiers or mass nouns with mismatched mass classifiers)
In the present study, we (1) re-examine if processing of classifiers are syntactic based or semantic based and (2) investigate if there is count/mass distinction by classifiers in Japanese. We hypothesize that if there is grammatical count/mass distinction by classifiers: (1) there should be ERP components related to syntactic processing (E-LAN or LAN), (2) distinctive signature should appear when the violation takes place across count and mass categories in contrast to the violation within a category. In addition, we tested the violation of the animal/non-animal boundary to examine the effect of these most basic linguistic categories.
2.
Method
2.1.
Participants
18 healthy and right-handed adults with no visual impairment (10 males and 8 females, mean age = 22.069) have participated in the study.
2.2.
Stimuli
Stimuli are 480 pairs of nouns and classifiers, which divided into 8 different conditions: (A)Count-noun match, (B)Count Within-mismatch, (C)Count Across-mismatch, (D)Count Animal-mismatch, (E)Mass-noun match, (F)Mass Within-mismatch, (G)Mass Across-mismatch, (H)Mass Animal-mismatch. For condition (A)-(D), the same 60 words (object names) were used, and the same 60 words (substance names) were used for condition (E)-(H). Thus, participants see an object name and a substance name four times each throughout the experiment. In condition (A), an object name is followed by an appropriate classifier such as enpitsu (pencil) followed by ni-hon (2 + classsifier for pencil). In contrast, in the condition (B)-(E), the word pencil is followed by a classifier mai (classifier for flat objects), hai (classifier means “a cup of”), hiki (classifier for relatively small animals) respectively. In condition (F)-(H), a substance name such as abura (oil) was followed by classifier bin (“a bottle of”), katamari (“a chunk of”), mai (classifier for a flat object), and tou (classifier for relatively big animal) respectively.
All nouns and classifiers used in the study were chosen based on a web rating test of 1-5 scales. 30 adults who did not participate in the ERP experiment were tested (12 males, 18 females, mean age = 21.27). 70 count nouns and 64 mass nouns were first chosen from commonly used vocabulary and each noun was paired with 5-7 classifiers including expected “matched” classifiers and “mismatched” classifiers. The degree of match for the pairs used in the main experiment were judged to be high in all “match” pairs and low in all “mismatch” pairs (Average rating score: (A)4.69, (B)1.08, (C)1.07, (D)1.02, (E)4.51, (F)1.53, (G)1.18, (H)1.05).
2.3.
Design & Procedure
In line with the study by Sakai et al., this study used word-classifier pairs instead of sentences. The stimuli were visually presented on a screen in 24pt white letters on a black background. There is no delay between the display of a name of object/substance and classifier. When "?" was presented afterwards (25 % of the time) participants pressed "correct" or "incorrect" button judging if the previous word and the classifier match or not.
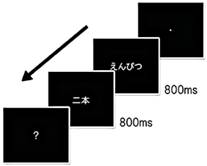
Fig. 1: After the fixation, participants see a name of object/substance for 800ms followed by a classifier also presented for 800ms.
The experiment was divided into two separate blocks each of which the match and the mismatch conditions including count nouns and those including mass nouns were tested separately with a break in between (the count-noun block: condition (A)-(D) and the mass-noun block: condition (E)-(H)). The order of the blocks was counterbalanced across participants, and the two blocks were tested on separate days for some participants when needed. All word-classifier pairs were shown in a random order within a block. Participants were also shown 240 match pairs involving non-target nouns in total as fillers in order to balance the number of the matched pairs and the mismatched pairs. Twelve questions were presented as the practice phase in the beginning of the experiment.
3.
ERP Recording and Analyzing
ERPs were recorded from 32 electrodes (Fp1, Fp2, F3, F4, C3, C4, P3, P4, O1, Oz, FC3, FC4, CP3, CP4, F7, F8, T7, T8, P7, P8, FT7, FT8, TP7, TP8, Fz, Cz, Pz, FCz, CPz, Oz). Also, an electrode was placed at the side of each eye to record eye movements. All channels were referenced to the left mastoid. Sampling rate was set to 1000 Hz and band-pass filters were dc-30 Hz. Recorded data was off-line re-referenced to both mastoids. All events with artifacts were removed by artifact rejections and manually removed through visual inspection. ERPs were averaged by an epochs of 1000ms duration including a 100ms pre-stimulus baseline after a band-pass of 0.1-30 Hz and then ground averaged.
4.
Results
4.1.
Error Rate
Error rates were 4.56% (SD=2.57) for the count-noun block and 5.24% (SD=2.02) for the mass-noun block.
4.2.
ERPs
ERPs peaking around 400ms were observed for all mismatch conditions, and 350-500ms after the onset of stimulus was chosen to be the time window by inspection of individual participants’ data (Fig. 2). The difference between the match and the mismatch conditions was maximum at the center of the scalp (Cz), suggesting it to be N400 effect. A repeated measure ANOVA was performed at the 350-500 time window for each block.
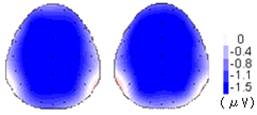
Fig. 2. Topography of the combined result from the two blocks at the 350-500ms time window. Similar negativity was observed for both Within-category violation (left) and Across-category violation (right).
4.2.1.
Count-Noun Block
For the count nouns, broadly distributed negativity was observed in all three mismatch conditions (Within the count/mass category, Across the count/mass categories, Across the animal/non-animal categories) in comparison to the match condition. In order to test whether the negativity is N400 or not, we first tested the effect along the median line. Electrodes around the median line were clustered into three regions: Anterior (Fz, F3, F4), Center (Cz, C3, C4), Posterior (Pz, P3, Pz). The main effect of Condition (F(3, 51)=13.552, p<0.01) and Condition*Region interaction (F(6, 102)=5.429, p<0.001) was observed. Post hoc analyses has revealed significant differences between the match condition (condition (A)) with each of the three mismatch conditions (condition (B)-(D); Bonferroni corrected p<0.001). However, there was no difference among the three mismatch conditions (Bonferroni corrected p=1.00 for (B) vs. (C), (B) vs. (D), and (C) vs. (D)).
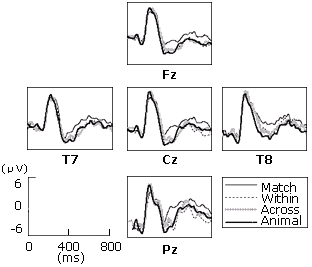
Fig. 3. ERP waveforms from the count-noun block at the selected five electrodes.
Secondly, electrodes were again clustered into four quadrants: left anterior (F7, F3, FT7, FC3), right anterior (F8, F4, FT8, FC4), left posterior (P7, P3, TP7, CP3), right posterior (P8, P4, TP8, CP4)). 3-way ANOVAs revealed that there is main effect of Condition (F(3,51)=11.597, p<0.001). However, no interaction between Region (anterior-posterior) and Condition (F(3,51)=0.135, p=0.939) or Laterality (left-right) and Condition (F(3,51)=0.365, p=0.778). Here, post hoc analyses also showed that the main effect of the Condition was only significant between the match condition and each of the three mismatch conditions (Bonferroni corrected p<0.01). No effect of Condition was found among the mismatch conditions (Bonferroni corrected p=1.00 for (B) vs. (C), (B) vs. (D), and (C) vs. (D)). The negativity observed in 350-500ms time window was distributed equally from the scalp center, and not lateralized in the left hemisphere. This suggests that the negativities observed in all mismatch conditions were N400, a signature of semantic-based processing.
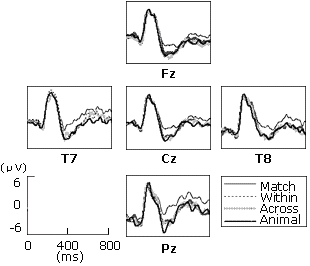
Fig. 4. ERP waveforms from the mass-noun block at the selected five electrodes.
4.2.2
Mass-Noun Block
The same procedure was taken to analyze the data from the mass-noun block. Two-way ANOVA was done for the median line, and the main effect of conditions were found (F(3,51)=10.248, p<0.001). The main effect of Condition was only significant between the match condition and each of the three mismatch conditions (Bonferroni corrected p<0.03). No effect of Condition was found among mismatch conditions ((B) vs. (C): p=1.00; (B) vs. (D): p=0.391; (C) vs. (D): p=1.00). However, the interaction between Condition and Region was not significant (F(6,102)=0.365, p=0.899).
We used the same four regions (left anterior, right anterior, left posterior, right posterior) again to analyze the lateralization. The main effect of Condition was found (F(3,51)=11.227, p<0.001). No interaction between Region (anterior-posterior) and Condition (F(3,51)=0.080, p=0.971) was found, and the ERP was not lateralized either (F(3,51)=0.451, p=0.718).
Again, post hoc analyses showed that the main effect of Condition was only significant between the match condition and each of the three mismatch conditions (Bonferroni corrected p<0.01). No effect of Condition was found among mismatch conditions (Bonferroni corrected p=1.00 for (B) vs. (C), (B) vs. (D), and (C) vs. (D)).
5.
Discussion
N400 effects were similar across all mismatch conditions compared to the match condition in each block. Interestingly, the mass-noun match condition (E) which is consisted of “matched” word-classifier pair showed N400-like effect in contrast to the count-noun match condition (A). Kutas and Hillyard have reported that the amplitude of N400 effect is an inverse function of the subject’s expectancy (1984). We hypothesized that, though stimuli in the present study have carefully chosen through the web rating task, the “matched” word-classifier pairs in the mass-noun block were still unexpected for the participants because mass nouns do not bear one-to-one relations with classifiers but accompanied by a variety of classifiers (e.g. “a cup of” water, “a bottle of” water, “a glass” of water). On the other hand, count nouns often hold one-to-one relations with classifiers, thus there is a lower possibility of unexpected classifiers in the count-noun match condition.
The mass-noun mismatch conditions (F)-(H) were analyzed in contrast to the match condition (E). Even though(E) was a control condition, it still elicited N400 effects and this fact might have caused a weaker effect in the mass-noun block resulting no Condition*Region interaction at the median line.
It is also notable that as Sakai et al. (2004) claimed, the N400 effects in the study were positioned in the centro-anterior region unlike typical N400. We speculate that classifier processing might involve a slightly different processing compared to noun-noun mismatches.
6.
Conclusion
If the count/mass distinction is grammatically marked by classifiers in Japanese, the mismatched pairs of words and classifiers should elicit ERP effects indicating the syntactic violation especially when they are each drawn from the count category and the mass category. However, we did not find a signature of syntactic-based processing. There is no grammatical count/mass distinction by Japanese classifiers, but the matching of words and classifiers are instead processed semantically. In other words, the results indicate that this distinction is not realized at the level of classifiers. Also, the observed N400 components were fairly identical among all mismatch conditions suggesting the matching of words and classifiers are independent of the classifier categories.
Reference
[1]. Barber, H. and Carreiras, M. (2005) Grammatical gender and number agreement in Spanish: an ERP comparison. Journal of Cognitive Neuroscience, 17. 137-153.
[2]. Bisiacchi, S. Mondini, A. Angrilli, K. Marinelli, & Semenza, C. (2005). Mass and count nouns show distinct EEG cortical processes during an explicit semantic task, Brain and Language 95, 98–99.
[3]. Cheng, L. & Sybesma, R. (1999) Bare and not so bare nouns and the structure of NP. Linguistic Inquiry 30 (4).
[4]. Chierchia, G. (1998). Reference to kinds across languages. Natural Language 69 Semantics, 6, 339-405.
[5]. Friederici, A. D. (2002). Towards a neural basis of auditory sentence processing. Trends in Cognitive Sciences, 6, 78-84.
[6]. Imai, M. & Mazuka, R. (2003). Re-evaluation of linguistic relativity: Language-specific categories and the role of universal ontological knowledge in the construal of individuation. In D. Gentner & S. Goldin-Meadow (Eds.), Language in Mind: Advances in the issues of language and thought. MIT Press. 430-464.
[7]. Imai, M. &; Gentner, D. (1997). A crosslinguistic study on constraints on early word meaning: Linguistic influence vs. universal ontology. Cognition, 62, 169-200.
[8]. Kutas, M., & Hillyard, S. A. (1980). Reading senseless sentences: Brain potentials reflect semantic incongruity. Science, 207, 203-205.
[9]. Kutas, M., & Hillyard, S. A. (1984). Brain potentials during reading reflect word expectancy and semantic association. Nature 307, 161-163.
[10]. Lakoff, G.(1987). Women, Fire and Dangerous Things: What Categories Reveal about the Mind. Chicago: University of Chicago Press.
[11]. Lucy, J. A. (1992). Grammatical categories and cognition. A case study of the linguistic relativity hypothesis. Cambridge: Cambridge University Press.
[12]. Mizuguchi, S. (2004): Individuation in Numeral Classifier Languages. Tokyo: Shoohakusha.
[13]. Mueller, J. L., Hahne, A., Fujii, Y., & Friederici, A. D. (2005). Native and nonnative speakers' processing of a miniature version of Japanese as revealed by ERPs. Journal of Cognitive Neuroscience, 17, 1229-1244.
[14]. Münte, T. F., Heinze, H. J., & Mangun, G. R. (1993). Dissociation of brain activity related to syntactic and semantic aspects of language. Journal of Cognitive Neuroscience, 5, 335–344.
[15]. Quine, W. V. (1969). Ontological relativity and other essays . New York: Columbia University Press.
[16]. Sakai, Y., Iwata, K., Riera, J., Wan, X., Yokoyama, S., Shimoda, Y., Kawashima, R., Yoshimoto, K., & Koizumi, M. (2006) An ERP study of the integration process between a noun and a numeral classifier., Cognitive Studies, 13(3), 443-454.
[17]. Steinhauer, K., Pancheva, R., Newman, A., Gennari, S., Ullman, M. (2001) How the mass counts: an electrophysiological approach to the processing of lexical features, Neuroreport, Vol. 12(5), 999-1005.
[18]. Tsai, S. (2009): “Processing of chinese Classifier-Noun Agreement: An Event-Related Potential Study”, Masters diss., National Cheng Kung University.