プロジェクト科目助成費-A(プロジェクト科目研究) 報告書
| プロジェクト名 | ネットワークコミュニティ | ||
| プロジェクトリーダー氏名 | 金子郁容 | 所属・職名 |
政策・メディア研究科 教授 |
| 研究テーマ | コミュニティウェア | ||
研究組織 |
||
氏名 |
所属・職名・学年等 |
研究分担課題 |
| 金子 郁容 | 政策・メディア研究科 教授 |
コンセプト開発 研究リーダー |
| 北山 聡 | 同研究科 博士課程3年 |
コンセプト、メソッド(ネットワーク分析)研究 |
| 高橋 正道 | 同研究科 修士課程2年 | メソッド(ネットワーク分析)の研究開発/実装 |
| 久保 裕也 | 同研究科 修士課程2年 | メソッド(知識共有システム基盤)の研究開発/実装 |
植村 徹 |
同研究科 修士課程1年 |
研究補助/実装 |
以上 5名
報告書目次
研究A コミュニティの状態、及びその中での個人の状態のフィードバック A-1. 概要
A-2. 目的
A-3. ネットワークコミュニティ支援
A-4. 組織アウェアネスの欠如とコミュニティガヴァナンスへの応用
A-5. 関係性フィードバックシステムの実装
A-6. MLサービスの実施
A-7. 運用実験の実施
A-8. 運用実験の結果と考察
A-9. まとめ
| 研究B | コミュニティメンバーによるコミュニティ運用ルールの構築と情報編集 |
B-1. 概要
B-2. 問題の背景
B-3. Web Structured Data Management Modelについて
B-4. プロトタイプシステム
B-5. システムの構成
B-6. システムの運用に必要なもの
B-7. インターフェイス構成
B-8. 利用画面例
B-9. プロトタイプシステムの応用事例
B-10. 評価
B-11. 考察
B-12. まとめと今後の課題
1.研究の背景
我々ネットワークコミュニティプロジェクトでは、興味関心に基づいた自発的な組織をコミュニティと呼んでいる。一般に、組織を想定する場合は、組織全体の目的を頂点とし、個人の目的や役割、情報の伝達経路等がトップダウン/ヒエラルキー的に分割・配置されることが前提になる。一方、コミュニティでは、個々の参加者の目的や意識は、それぞれの自発的な価値観に基づいて動的に構成されたものである。それゆえ、その組織原理はもちろん、組織化プロセスは、企業や行政組織などと比較して異なるものになると考えられる。本プロジェクトでは、この組織原理、組織化プロセスの記述/解明に加え、従来の方法では解決しにくい、あるいは問題とさえされない諸問題(ネットワーク上のガヴァナンス/環境問題/教育/障害者雇用/行政への市民参加)への適用を提案、試行することを目的としている。本研究グループでは、諸問題のうち特にネットワーク上のガヴァナンスに焦点をあてて研究を進めることにする。
2
.これまでの研究成果本プロジェクトでは、コミュニティ全般の文献調査や事例研究と共に、その研究成果を実際に存在するコミュニティ上に適用する各種の試みを行うことで、実社会に貢献してきている。さらに、こうした実社会への研究成果の適用をもとに理解を深めるという、スパイラル状の研究手法を確立している。特に、本研究グループがこれまでに実社会に対して研究成果を適用した例として、
藤沢市地域情報化プロジェクト 「電縁都市ふじさわ」:
→ コミュニティ生成/運用の実証実験
障害者雇用情報化プロジェクト 「Challenged Working
Forum」
→ コミュニティの多面的なシステム構築と運用
Nomosシステムの開発
があげられる。
以下にそれぞれの今までの成果(共に現在進行中であるが)を概説する。
「電縁都市藤沢」ではCommunity Makerというコミュニティを作成/運用し、コミュニティ群を容易にサポートできるコミュニティウェアを使用している。このプロジェクトは、市民から行政への直接的フィードバックシステムではなく、同じ問題を共有する市民同士の情報共有/相互編集の場としてコミュニティを捉え、そこで編集された共有知を行政にフィードバックするという画期的な取り組みである。我々は、本プロジェクトのこの全体の運用ポリシー作成や運用自身にコミットし、コミュニティガヴァナンスの実際的応用の経験を得ることができた。
また、「Challenged Working Forum」では、Job Matching Systemと呼ばれる企業側の雇用ニーズと被雇用者側の条件(働く環境・時間など複雑な条件がある)を定型的マッティングさせるシステム、MLの利便性とWebの公開性を連動させたコミュニティウェアWeb-ML、障害者雇用の専門家によるコンサルティングなど情報システム論に終始しないコミュニティを多面的な統合を目指したより広い意味でのトータルコミュニティウェアを構築し運用している。なお、これら2つのプロジェクトは、実験的段階から実用段階やネットワーク上のコミュニティとしてのケーススタディ的な研究領域としても期を熟しつつある。また、今年度は、前者では環境保護条例/都市マス関連の話題が議題として取り上げられ、後者では企業、障害者の参加者が徐々に増えてきたこともあり、本来の目的の質的な変化が問われる段階にある。
「Nomos」とは、RDBMSにおけるデータ構造・スキーマ構造の双方に対して、WWWクライアントからの統一的なインターフェイスによって新規作成・編集・削除といった操作を行えるものとし、さらにこの操作権限をマルチユーザー化したデータベースモデルである。これは、従来的なRDBMSの構築・運用における、データベーススキーマデザインの主体、アプリケーションデザインの主体、ユーザーとしての主体の隔絶的な関係を解消し、RDBMSそれ自体をコミュニティウェアとして再提案したものである。Nomosは、ネットワークコミュニティ内のグループウェアとして、また本プロジェクトのメンバーの修士研究のためのアンケート収集システムなどとして利用され、多様な参加者が分散的に情報を記述し構造化するためのツールとして有効であることを示した。
3.研究の目的
コミュニティは、知的・物理的に共有された何らかの価値を扱う場であり、そこでは、この価値の創出・分配・利用についての相互的・自発的なガヴァナンスが行われている。電子ネットワーク上では、ガヴァナンスに伴うコミュニケーション行為が記録されるため、これを対象として定量/定性的な分析を行えることが特徴である。また、単にコミュニケーションメディア上に構成されるコミュニティの分析にとどまらず、コミュニケーションメディアそのものを設計・実装・運用することで、コミュニティガヴァンナンスの原理を操作的に解明することができると考えている。
次に、関連する先行研究として、従来的なグループウェア研究との対比を述べる。これまで、グループウェア研究は、認知科学・文化人類学・行動科学など、学際的研究分野として注目されてきた。これらの研究は、主に「グループ」という十分に組織化された中での意思決定や共同作業を支援することに関心の重点が置かれている。一方、我々が研究の対象とするのは、組織化のプロセスや運用自体に焦点をあて大きくわけて次の2点についてのモデル構築、及びプロトタイプ的な実装を行うことを目的とする。
コミュニティ内の発言構造(コメントツリー)に着目し、コミュニティのマクロ的な動態やその中での個人の状態を定量的に捉え、コミュニティガヴァナンス(フレーミングの軽減、意志決定指標、コミュニティの対外的な認知促進)への応用を考察し、それを基づいたインターネット上のアプリケーションを実装/運用する。
コミュニティを創発させるようなコミュニケーション環境となり、コミュニティの活動を誘導・支援する機能をシステムに内包したメディアを構成するための理論構築。
このように、我々の取り扱う問題領域は、既存のグループウェア研究とは基盤を異にするものであるため、これを「コミュニティウェア」と呼び分けるものとする。コミュニティウェアは、ユーザをシステム運用の分散的主体として見なし、ユーザ間の自発的な関係性の構築をもって、システムを創発的に発展させるドライビングフォースとして作用させようという構造的意図に基づいたデザインがなされたものであると定義する。
4.研究報告
| 研究A | コミュニティの状態、及びその中での個人の状態のフィードバック |
A-1. 概要
研究Aでは、自発的参加を前提として、情報の共有や編集を目的とする、境界が曖昧な組織を「ネットワーク・コミュニティ」と呼び、その支援スタンスを組織生成を支援することを特徴とするコミュニティウェアの流れに位置づける。
また、対面性を伴う組織コミュニケーションで無意識のうちに伝わってくる、「他者の存在や他者との関係、組織の存在や動態」が組織内外から認識されることを「組織アウェアネス」と呼ぶ。そして、この「組織アウェアネス」が、メーリングリスト(以下
ML)などのように相づちが打てなく、時間的に間延びしがちで、多くの場合文字ベースで行われる、ネットワーク・コミュニティで欠如していることを問題とする。この「組織アウェアネス」の欠如によって引き起こされる弊害として、過剰に感情的なやり取りが引き起こすフレーミング(flaming)を取り上げ議論する。そして、フレーミングの軽減を含めて、「組織アウェアネス」をネットワーク・コミュニティの管理/運用/調整 ― コミュニティガヴァナンス ― に応用する提案を行った。更に、組織コミュニケーションツールとして最も普及している
MLを対象とし、「組織アウェアネス」を促すために、その発言間構造をネットワーク分析して抽出された組織構造的指標である「Network Status」を、「ネットワーク・コミュニティ」の内外にフィードバックする「Network Status Browser(以下NSB)」を開発した。なお、研究Aでは、
NSBの評価を行うための資源収集を目的としてMLサービスを行い、実際に稼働する200程度のMLの中でNSBを1ヶ月半程度運用した。そして、実験後にアンケート調査による定性的な評価、及びNSBの使用/不使用による各指標値への定量的な影響評価を行った。また、NSBを使って実際にどのような分析や解釈が可能であるかを示すために、MLの管理者と電子メールでディスカッションを行い、これを参考としてMLの文脈(コンテクスト)によるNSBの構造的な解釈を行いその可能性を考察した。
A-2. 目的
MLのように相づちが打てなく、時間的に間延びしがちで、多くの場合文字ベースで行われる非同期型の組織コミュニケーションにおいて、「組織アウェアネス」の欠如による弊害を指摘し、「組織アウェアネス」を使った組織コミュニケーション支援について考察する。
「組織アウェアネス」促すコミュニティウェア「Network Status Browser」をデザイン/実装する。その際、運用段階で「クリティカルマスの問題」を軽減させるため、非同期の組織コミュニケーションツールとしては現在最も普及しているMLにアドオン(追加)する形で実装する。
システム評価のための研究室内の人員や少数の被験者ではなく、広域的なMLサービスを行い、実際に稼働している多くのMLを対象に「Network Status Browser」を運用させその評価を行う。また、システムの運用をある程度初期の段階において行い、ユーザーからのフィードバックを開発プロセスに反映させる。なお、定性的な評価として、心理的影響をアンケート、及びMLの管理者へのインフォーマルなディスカッションを交えて行う。更に、その定量的な評価として、MLの発言ログから抽出されるいくつかのマクロ的指標に対する影響に対する仮説を検証する。
A-3. ネットワークコミュニティ支援 ~ グループウェアからコミュニティウェアへ ~
組織とコンピュータメディアについて1980年代後半より学際的に研究しているCSCW(Computer-Supported Cooperative Work)にグループウェアという研究領域がある。最も有名なClarence A.Ellisのグループウェアの定義によれば、「共通の仕事や目的を持って働くユーザーグループを支援し、共同作業環境へのインターフェースを提供するコンピュータシステム」を指す。この定義の中では支援する対象を、「共通の仕事や目的をもって働くユーザーズグループ」としている。ところが、従来のグループウェア研究をサーベイしたところ、支援する方法については詳細に議論されているが、支援する組織の形態や特性、更にそのグループウェアがどのような社会的文脈の中で必要とされているのか、についてあまり言及していないように思われる。研究Aでは、コンピュータを介したコミュニケーション - Computer-Mediated Communication(以下CMC) - の社会的普及によって出現した、「自発的参加を前提として、情報の共有や編集を目的とする、境界が曖昧な組織」を「ネットワーク・コミュニティ」と呼び、これを支援することに焦点をあてる。また、このような「ネットワーク・コミュニティ」を支援する学術的な動きは、ここ数年でようやく見られるようになり、我が国でも「コミュニティウェア」という用語を掲げたワークショップや国際会議が開催されている。研究Aは、このグループウェアからコミュニティウェアという流れの中に位置づけられるが、その取るべきスタンスとして次の3点を強調しておく。
CMC技術の発展や可能性に焦点を置くのではなく、「ネットワーク・コミュニティ」という実際に存在する組織の形態や特性を十分に議論する。 「ネットワーク・コミュニティ」には、何が不足してどのような問題が生じているのかを捉える。 「ネットワーク・コミュニティ」の技術的支援を行うべき領域を明確にし、そのバランスを考慮する。
A-4. 組織アウェアネスの欠如とコミュニティガヴァナンスへの応用
研究Aでは前述したスタンスを踏まえ、対面を伴う組織コミュニケーションの中で無意識の中で感じている「他者の存在や他者との関係、組織の状態や動態」が「ネットワーク・コミュニティ」に欠如していることを問題として取り上げる。実際に、CMCに関する社会心理学的な先行研究でも、CMC上の「他者への配慮に欠けるメッセージ」や「受け手の存在の希薄さ」は、対面では無意識に交換される言葉以外の音声や身振り手振りなどノンバーバルな情報、すなわち「社会的手がかり」の欠如によって引き起こされる、と指摘している。研究Aでは、このような「他者の存在や他者との関係、組織の状態や動態」が組織内外から認識されることを「組織アウェアネス」と呼ぶことにする。実際に、この「組織アウェアネス」の欠如が、MLやパソコン通信上の電子会議室においてフレーミング(flaming)に発展するケースも報告されている。なお、アウェアネス(Awareness)とは「気づき」の意味で、グループウェアにおいても1990年代初期から「人間の存在や状況を認識させ、作業者同士の偶発的なコミュニケーションを誘発する」といった視点で研究がなされている。一方、コミュニティウェアでは、主に個人の趣味趣向のマッチングなどの「Interest Awareness」の研究が盛んに行われている。研究Aでアウェアネスの対象とするのは、こういった趣味趣向などの「個人的な情報」ではなく、組織内コミュニケーションによる「関係の蓄積」、すなわち、社会学者のコールマンのいう「ソーシャルキャピタル(関係資本)」の一側面をネットワーク・コミュニティ内外に意識させるような情報である。
研究Aでは、このような「ネットワーク・コミュニティ」上の既存のトラブルの回避に加えて、「組織アウェアネス」の促進が「ネットワーク・コミュニティ」の管理・運用・調整にも応用可能であると考えている。そして、フォーマル/インフォーマルを問わず「ネットワーク・コミュニティ」における意思決定や意見調整、成員の参加/退出時の再編(役割変更や依頼)、情報編集など、各人の自発性と相互作用に基づく ― 自律分散的な ― 統治のことをコミュニティガヴァナンスと呼び「組織アウェアネス」のコミュニティガヴァナンスへの応用も考察した。
A-5. 関係性フィードバックシステム「Network Status Browser」の実装
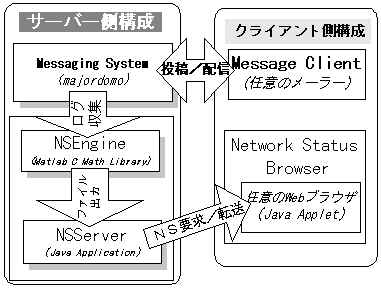
以上のような「ネットワーク・コミュニティ」の「組織アウェアネス」を促進するために研究Aでは、「Network Status Browser(以下NSB)」と呼ばれる情報システムを開発した。このNSBは、組織コミュニケーションツールとして最も普及しているMLに追加する形で実装した(図 1)。
MLでは発言ログという形で誰と誰がコミュニケーションを取ったかという関係が蓄積される。この関係を、ML内の全ての発言について調べれば、「誰と誰がどれだけ会話をしたのか」という行列データ(ネットワークデータ)が得られる。そして、この行列データに対して、「ネットワーク分析」と呼ばれる関係構造分析の手法を適用すると、MLの構造を表すミクロ的指標や、全体の大まかな状態を表すマクロ的指標、及びその時間的推移等が抽出できる。NSBは、これらの組織構造的な状態を「ネットワーク・コミュニティ」のメンバーにフィードバックし、「組織アウェアネス」の促進を目的としていている。
なお、このNSBのデザインに際して、表 1に示すように、その対象としてMLのメンバー(参加検討者、新規参加者、既存参加者)、MLの管理者/コーディネータ、サイト運営者、CMC研究者、などの4つの主体に対して次のような応用例を想定した。
表
1 4つの主体とNetwork Status Browser(NSB)の応用例| 主体 | 応用例 |
|
MLメンバー |
参加検討者 |
発言形態や組織規模を把握して、話し合われている内容加えて「話し合い方(発言の集中度や返信率等)」を参加前/参加直後に把握 |
新規参加者 |
||
既存参加者 |
|
|
ML管理者 コーディネータ |
|
|
サイト管理者 |
|
|
CMC研究者 |
|
|
このNSBの表示方法とそこでどのような情報が閲覧できるのかを概説したものをNSBの画面のキャプチャと共に表 2に示す。
表
大分類 |
表示方法 |
閲覧可能な指標 |
図 |
MLのミクロ的指標 |
ネットワーク図 |
クリーク(派閥)、リエゾン(仲介者)、オピニオンリーダー(中心者)の把握 他者との方向性別のコミュニケーションの頻度 |
 |
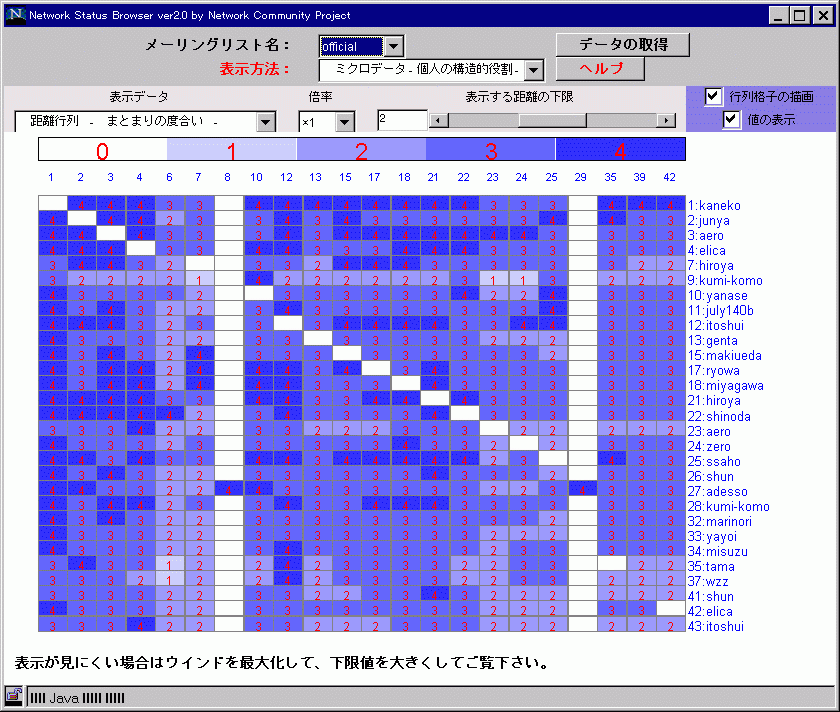
距離行列 |
距離行列 (全てのメンバーとの親密度) |
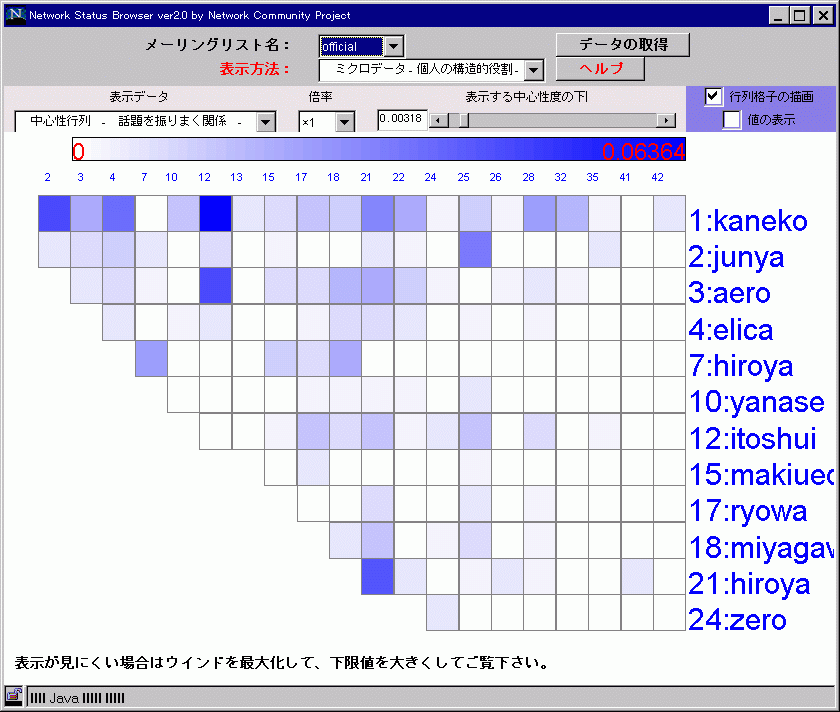 |
|
中心性行列 |
中心性行列 (話題を作る関係) |
 |
|
MLのマクロ的指標 |
MLの時間的推移 |
発言数/返信数/発言者数/累積発言者数/参加者数/発言率/密度( density)/直接結合度(cohesion)の時間的推移(月/週/日単位) |
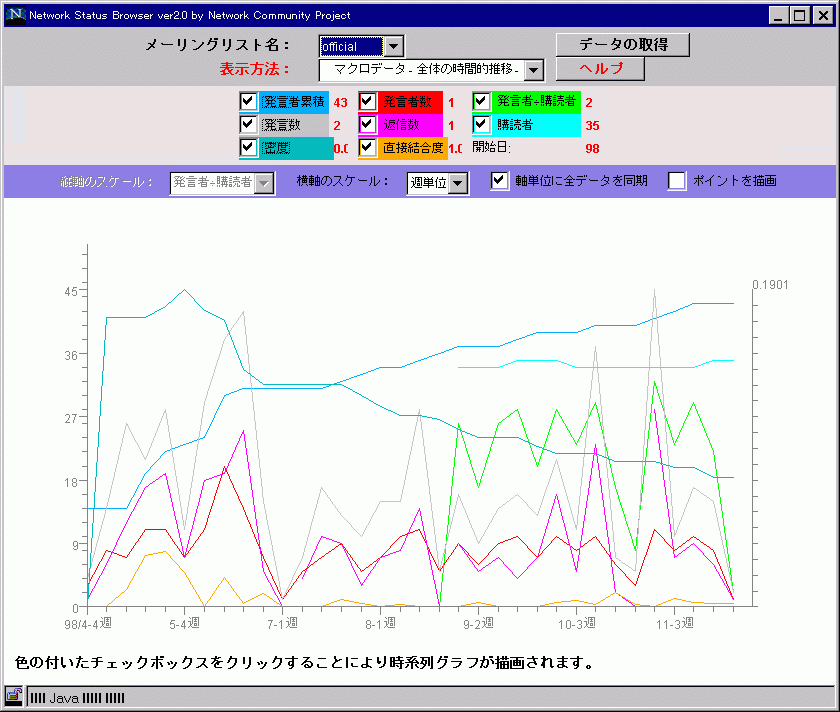 |
個人のミクロ的指標 |
個人発言特性 |
個人の発言形態を、発言の多さ、発言を引き込む力、話題を作る力、により 3次元表示 |
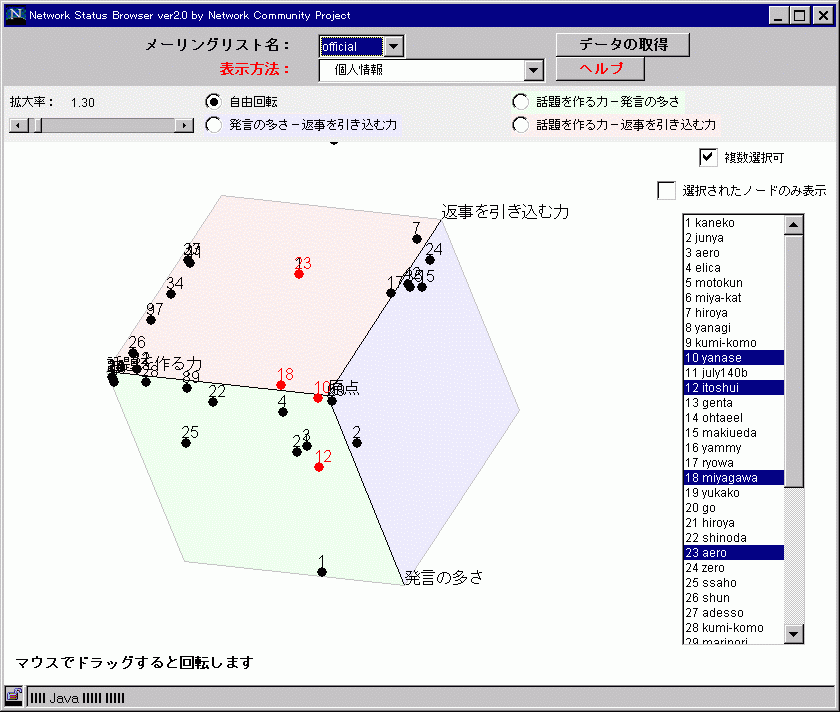 |
ML間の比較 |
MLランキング |
他の MLとのマクロ特性による比較 |
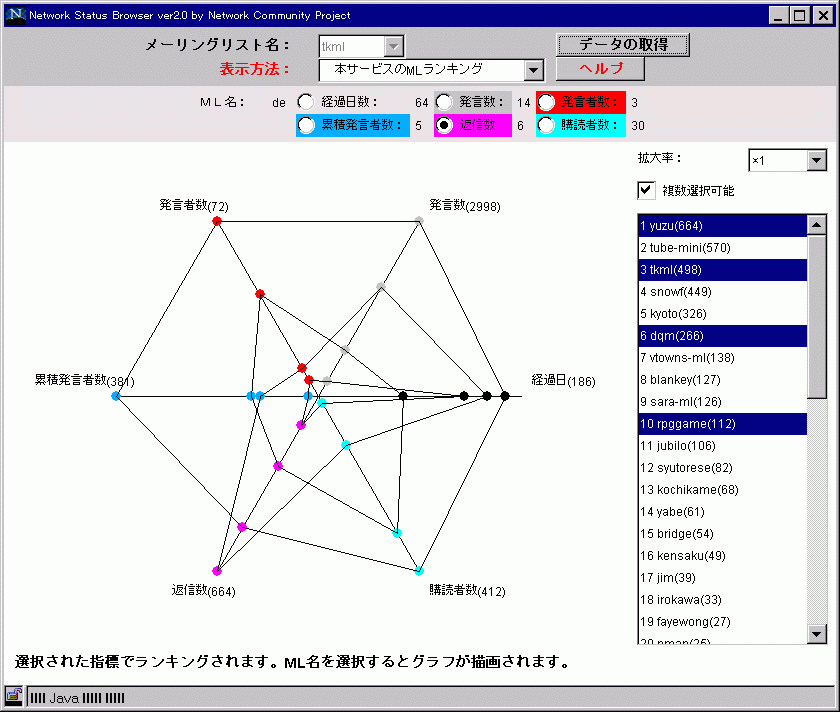 |
A-6. MLサービスの実施
研究Aでは、運用時と同じMLのデータを使った開発プロセスの展開、実際に多くのユーザーに利用された中でのソフトウェア評価を行うために、システム導入以前の5ヶ月前(1998年5月28日開始)より、学術研究協力を条件とした無料のメーリングリストサービスを始めた。研究者にとって、このようなサービスは次のような利点がある。
CMC組織の立ち上げ時からのデータを調達できる
- 研究協力に対する理解が得られやすい
- 導入前後の影響把握に加えて
CMC研究の対象となっているのは主に活発な組織であるが、このように研究資源の独自調達により活発でないCMC組織や、活発でなくなったCMC組織の動態を探求することができる 研究協力に同意した CMC組織は、研究協力が第一の目的ではなく、ニーズベースに基づいて発足されたCMC組織であるので、より一般的なデータ収集が可能であるこのサービスの利用状況は、サービス開始以来現時点まで
218件の申請があった。その中で1998年12月18日の時点で稼動しているものは163件であり、そのサービス全体の基本統計値を表 3に示した。
表
経過日 |
発言数 |
返信数 |
参加者数 |
|
平均 |
76 |
196 |
55 |
25 |
中央値 |
68 |
58 |
12 |
11 |
標準偏差 |
64 |
422 |
107 |
50 |
合計 |
12388 |
31951 |
9015 |
4102 |
最大値 |
229 |
2998 |
664 |
412 |
A-7. 運用実験の実施
運用実験は1998年11月1日から1998年12月18日まで行った。運用実験としては、次のような3つの運用実験を行った。
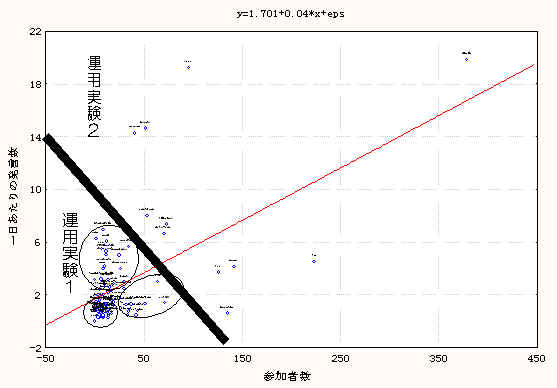
3つのクラスターに分け(図 2の実線より左下)、それぞれについて導入前後の効果を把握する
- 参加者数と発言頻度による違いにより
参加者数と発言頻度があまりに大きいためにクラスタリングのハズレ値については(図 2の実線より右上)、全てのMLでNSBを導入した。その後、管理者への電子メールによるインフォーマルなディスカッションを行い、NSBを使った分析や問題点を指摘してもらった1,2の実験開始後にサービス申請のあった MLに対して、発足当初よりNSBを利用したケースと使わないケースに分け、その効果を測定するなお、全ての運用実験において管理者の承諾を得た上で、
NSB使用対象者にチュートリアルを4回に分けて電子メールで送付した。
A-8. 運用実験の結果と考察
A-8-1. 運用実験
1における仮説検証と考察
運用実験1では約100のMLを対象として、独立変数をNSB使用/不使用、従属変数を各仮説中の指標値として、その平均値に統計的有意差が認められるかを検定した。
仮説1:NSBを使用したMLの方が、返信数の増加率が大きい。
仮説2:NSB使用/不使用に関して、MLの参加者数の増加率に差はない。
従属仮説1:NSBを使用したMLの方が、返信率の増加率が大きい。
従属仮説2:NSBを使用したMLの方が、密度の増加率が大きい。
従属仮説3:NSBを使用したMLの方が、直接結合度の増加率の平均値が大きい。
各仮説について帰無仮説を立て、
NSB使用/不使用を独立変数とした各指標値のt検定を行った結果、返信数と直接結合度の増加率に5%水準で統計的有意差が認められ仮説1、従属仮説1が支持された。また、参加者数の増加率については統計計的な有意差は認められず仮説2が支持された。以下、簡単に考察を行う。まず、発言数の増加率が統計的有意差を持たずに、返信数(ある発言への発言)についての仮説
2が支持されたことは、NSBは、発言数より返信数を増やす傾向がより強いといえるだろう。すなわち、NSBは単に発言を増やすのではなく、他者とのつながりをつけるという行為を触発したといえる。また、返信数を発言数で除して定義される返信率についての従属仮説2が支持されなかったのは、発言数自身に返信数が含まれることによってその効果が軽減されてしまったことが推測できる。また、分母を発言者数、分子を仮説1で言及されている返信数、を使って定義される密度と直接結合度のうち、直接結合度に言及した従属仮説3のみが支持された。これは、密度と直接結合度の定義を詳細に議論すればわかるように、密度が一方的な関係(発言者A→発言者B or 発言者B→発言者A)を分子としてカウントするのに対して、直接結合度は双方向的な関係(=返信数:発言者A→発言者B and 発言者B→発言者A)を分子としてカウントする。つまり、NSBによって、一方的な関係ではなく双方向的な関係が触発されている可能性が示されたといえる。
A-8-2. 運用実験
2における管理者とのディスカッション
~ NSBのコーディネーションツール、分析ツールとしてのポテンシャルの考察 ~
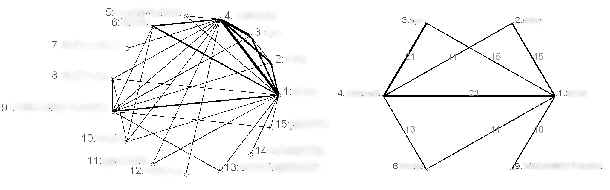
運用実験2の対象となったMLの管理者とのインフォーマルなディスカッションを含めて、NSBのネットワーク・コミュニティのコーディネーションツールやCMC(Computer-Mediated Communication)分析ツールとしての評価や可能性を考察した。ただし、本報告書では紙面の都合上その一部を紹介するにとどめた。また、MLの名称、及び電子メールアドレスの@マーク以前の文字列はプライバシー保護のために図中では塗りつぶした。これより、ネットワーク図の発言者と発言者をつなぐ線のことを紐帯(ちゅうたい)と呼ぶ。また、紐帯によって結ばれる発言者間でどれだけやり取りがなされているのかを紐帯の度数と呼ぶことにする。
ML(a) ~
ある管理者の管理する
ML(a)のマクロ的データを図 3に示す。この図を見てもわかるように、発足時当初(4月~9月)の発言数の増加はみられるものの、返信数や発言者数は全く増えていない。ところが、10月に参加者数が少し増えた際に、マクロ的な指標の推移に変化が現れたというのがはっきり見て取れる。このML(a)の管理者はこれ以外にもう一つMLを管理しており、これら2つのMLの実際の管理経験と、NSBの指標値を比較・分析することによって「盛り上げるコツ」のようなものを学び、それに基づいた行動を同時期に実践したということであった。そのポイントとは、「新規発言者には、どんな些細な返事でも行う」ことだいう。この効果は、10月以降に発言数の増加と共に返信数が増加し発言者数もそれに追随していることからも明らかである。また、このML(a)のネットワーク図(図 4)を見ると、3時の方向の管理者以外に2人ほど放射状に紐帯を張っている人の存在が確認できる。管理者は、この2人が自分(管理者)の行動変化に気づき、新規参加者に同じように振る舞ったことがMLの活性化のきっかけになったと指摘している。この事例では、MLの実際の管理経験とNSBによる分析による意識/態度変化が、他のメンバーに波及し、新規参加者を気軽に迎えるような雰囲気がMLに創発されたといえるだろう。
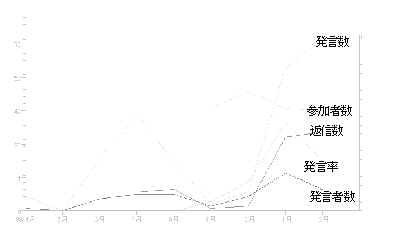

図 4 ML(a)のネットワーク図
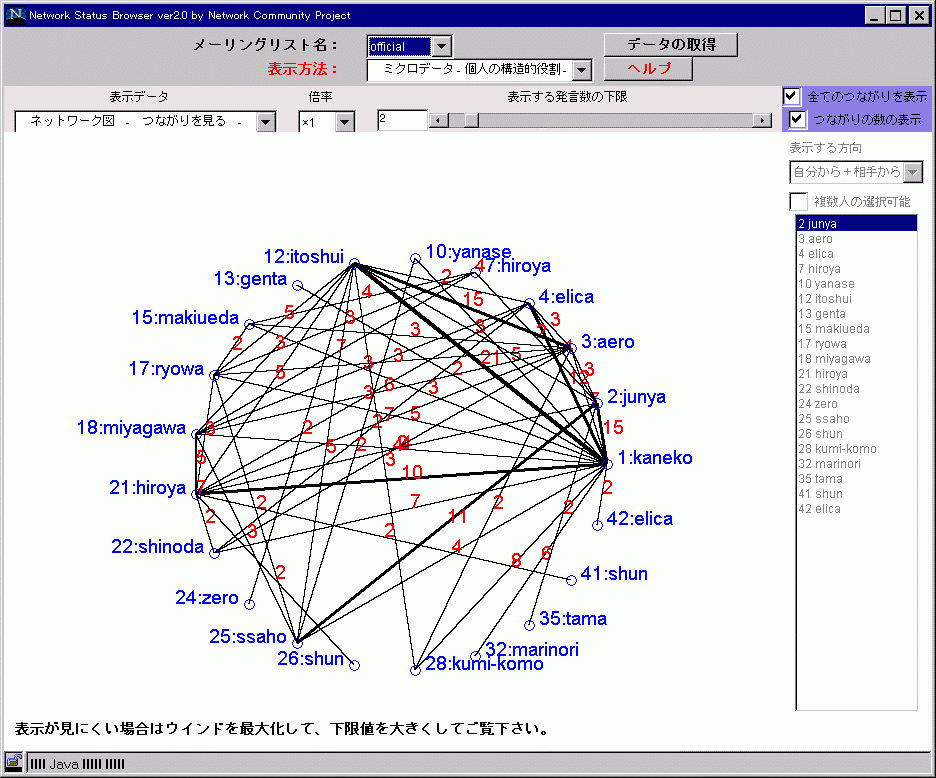
ML(b)は、元々友人関係(対面経験)のあるネットワーク・コミュニティである。対面経験があるので、そのメンバーへの心理的影響や態度変容は考えにくい。そこで、このML(b)には、筆者が構造的な側面だけからこのMLのメンバーのミクロ的な行動を分析し、その結果を管理者にみてもらいその実感と照らし合わせてみた。
この
ML(b)のネットワーク図(図 5)をみると、1, 2, 3, 4, 6, 9番の紐帯の度数が多く、中心的なメンバーだとわかる。その中でも、1, 4, 9番はかなり多くの人とやり取りをしていることがわかる。2, 3, 6番も発言は多いが、限られた人との頻繁なやり取りが多いことがわかる。このように分析結果を、管理者に尋ねてみたところ、おおむね実感と一致するということであった。しかし、3番は話題を振る人、逆に9番はそれほど話題を振りまいているとの感覚はない、とのことだった。これは、筆者が客観的に紐帯の本数を数えて「話題を振りまいている」としていたのに対して、管理者にとっては、紐帯の度数の総和の方がより「話題を振りまいている」というイメージに影響を与えていたと考えられる。実際に、紐帯の数は、確かに9番が8本、3番は4本で9番方が多いが、度数×紐帯では、9番が28(=10+3+5+3+3+2+1+1)であるのに対して、3番は42(=15+1+21+5)となり、3番の方が大きい。つまり、より多くの人と会話をするという構造特性の把握が、特定の人と発言の多い人の存在によって妨げられているといえる。もちろん、このML(b)の管理者への質問は実験的なもので、このような構造特性の判断違いによって実害はなかった。しかし、意志決定や意見調整時に「誰の意見が話題を呼んでいるのか」ということを判断する際に、発言数の多さによって余計なウェイトが加わってしまうことは好ましいとはいえない。このような感覚のずれと構造的側面の実態を客観的に可視化・分析できるNSBの特性を考慮すれば、ネットワーク・コミュニティ上の緩やかな意見調整を行う際の「盲点を気づかせるツール」としての応用も考えられる。以上見てきたように、
NSBは、ネットワーク・コミュニティにおけるコーディネーションツール/CMC分析ツールとしても、比較的基礎的な機能に限定した現在のバージョンでもかなり有効であることがわかる。MLは一つのアドレスにポストするとMLに参加している全員に配送される仕組みであるが、「そこには確かに組織構造(関係性)が形成(蓄積)されていて、文脈(コンテクスト)に裏付けられた意味がある」、ということを管理者とのディスカッションによって確認できた。
A-8-3. 運用実験
3における仮説検証と考察
運用実験3は、ML発足時からNSBを使用できる環境か否かを独立変数、仮説中の指標の増加率を従属変数として、その平均値に統計的有意差が認められるかを検定した。
仮説1:NSBを使用したMLの方が、発言者数の増加率が大きい。
仮説2:NSBを使用したMLの方が、MLの参加者数の増加率が大きい。
これらの帰無仮説を検定するために
NSB使用/不使用を独立変数とした各指標値の
t検定を行った結果、参加者数の増加率に5%水準で統計的有意差が認められ仮説2が支持された。また、発言者の増加率については、統計的な有意差は認められなかった。よって、帰無仮説2は棄却されず、仮説1は支持されなかった。以下、簡単に考察を行う。
まず、NSBを使用した方が、参加者数の増加率が大きいという仮説2については、運用実験3がML発足時から実験を行ったことが前提となる。実際に、この前提が成立しない運用実験1についてはこの仮説は支持されていない。今後の課題としては、より綿密なネットワーク・コミュニティ参加への心理的効果を、定性的なアンケートやNSBの提示情報別に捉えていくことがあげられる。また、支持されなかった発言者数についての仮説1についても、5%水準の統計的有意差は少しの差で認められなかったが(p= .0.53372)、その違いはほぼ確認できたといってもいいだろう。この仮説についても今回は、その差を確認するに留まっているが、より綿密なモデル化とそれに基づいた実験、あるいはエージェントシュミレーションなどによって、心理的変化や態度変化の内部プロセスを見ていくことができるだろう。また、NSBを使用して盛り上がるMLとそうでないMLの違いを比較することによって、NSBが有効に働く条件を確認することも、むやみに技術指向に陥ることを軽減するために必要である。また、運用実験1で支持された返信数の増加率、及びほぼ支持された発言数の増加率に大きな差が認められなかったのは、ML発足時から発言の活発でないMLはあまり考えられないことからも納得のいく結果だといえる。本論文では、これ以上のデータを取り扱っていないが、現在(1998年1月12日)もデータは一日ごとにとり続けているので、運用実験1のようにある程度の時間の経過した後にNSBを導入した事例との比較なども行えるだろう。
A-9. まとめ
研究Aでは以下のようなことを実現、確認、検証できた。
- 従来の社会心理学の研究と事前アンケートから、ネットワーク・コミュニティにおける「組織アウェアネス」の欠如を指摘した。「組織アウェアネス」の欠如をそれによる弊害、それを利用したコミュニティガヴァナンスについて考察した。
MLの発言間構造よりMLの組織構造的な特性やその時間的な推移が抽出できた。この抽出結果の妥当性や有効性は、実験後アンケートの定性的な評価、定量的な評価、及び各MLの管理者へとのディスカッションを含めた記述的な評価によって明らかにされた。 Network Status Browser(以下NSB)をJAVA言語で実装したことは、OSに依存しないという最も特徴的な側面より、運用実験前、直後おけるシステムの細かいチューニングに伴うプログラムの再配布、運用実験に伴うユーザーのマシンへインストールを不要にしたという側面から非常に有用であった。 MLサービス、運用実験全体としては、短期間に3つの実験を行い、それぞれから示唆に富む結果が得られたことは、研究Aで目的とした実際の利用の中でのグループウェア(コミュニティウェア)評価の有効性と現実性を実証できたといえる。 運用実験1では、NSBを使用した方が、返信数の増加率がより大きいという仮説が支持された。すなわち、NSBによって、他者とのつながりをつけるという行為を触発する可能性が示された。また、NSBを使用した方が、直接結合度の増加率がより大きいという仮説が支持された。すなわち、NSBによって、一方的な関係ではなく双方向的な関係を触発する可能性が示された。 運用実験2は、NSBネットワーク・コミュニティのコーディネーションツールやCMC分析ツールとしての評価や可能性を展望するために、MLの管理者に電子メールでインフォーマルなディスカッションを行った。その有効性と可能性についての管理者の意見はおおむね肯定的であった。ただし、その使いやすさ、わかりやすさは、親しみやすさ、については改善が必要であることも指摘された。 運用実験3では、NSBを使用した方が、参加者数の増加率がより大きいこという仮説が支持された。すなわち、ML発足時からNSBを使用した方がメンバーがより参加しやすい雰囲気が触発されたと考えられる。ただし、今回の実験ではその心理的な側面や参加プロセスの詳細は明らかにされていない。
B-1. 概要
たとえば,複数~多数の管理者が,インターネット規模で利用されるような 大規模な分散・連邦データベースを,自律分散協調的に管理・編集するという仕組みを 作り出すためには,データベースコンテンツの管理・編集ツールとしては, どのようなものが必要となるだろうか. 我々は,この問題を解く上での鍵として, ユーザや,ユーザがコンピュータシステムの中に 作り出すオブジェクトによって,有形無形の「まとまり」が自発し, それらの間に,あるパターンに基づいたメッセージング関係が生ずることに着目をしている. 我々は,これらを「コミュニティ」として捉えて,その活動を支援するような 「コミュニティウェア」を作り出すことが重要であると考え, 研究を進めてきている.
本報告書では,コミュニティのメンバーが,コミュニティの状態に基づいて, 自分達のコミュニティにとっての管理・意思決定を行うための ルールを動的に選択できるようなコミュニティウェアのデザイン問題について, 検討した事例を示す. 我々は,このようなコミュニティウェアなどのシステムのデザインは, ソフトウェアモジュール同士の疎結合性・動的再構成機能に基づいて 動作するような,自由度と応用性の高いものである必要があると考えている. しかし一般に,自由度と応用性の高い,多ユーザ分散的なシステムを運用したり 管理したりするというような作業は,複雑で実用性の低いものとなって しまうことが懸念される. そこで,このような分散化・疎結合化のパラダイムにおける 管理・運用の複雑性を単純化・低減するための手法について研究した.
本研究は,システム管理・運用の複雑性を単純化・低減するために, 情報項目同士の参照関係のブラウズ手法の開発と,そうした情報項目の 内容やその参照関係の更新の作業を,多ユーザ分散環境から行う場合における, 情報の一貫性保持のための必用条件を抽出し,これを Web Structured Data Management Model(Web SDM Model)と名付けた. また,今回独自に開発したデータベース機能と, そのhttpインターフェイスを,多ユーザ分散型のコミュニティウェアとして構成し, この中でWeb SDM Modelの実装を行った. また,このWeb SDM Modelの手法が, 実際のコミュニティウェアの中でどのように機能するかを 検証するために,このシステムをカスタマイズし, 複数のケースにおいて利用することを行い,モデルの再検討と修正を行った.
研究の成果としては,このWeb SDM Modelによる手法を, コミュニティメンバーによるコミュニティ運用ルールの基盤となるような, 「メタ・ルール」として位置づけることができた.このようなメタ・ルールは, コミュニティ運用ルールを規定するものであり, 今後引き続き,コミュニティウェア内でのコミュニティ運用ルールについて 研究する際の基盤とすることができると考えている.
B-2. 問題の背景
商用データベースの関連アプリケーションとして, ObjectStore社のObjectInspectorなどの, データベースコンテンツの管理・編集ツールがある.これらは,非日常的な局面で, 通常のアプリケーションからのデータベースに対する入出力操作を停止しておいて, データベースコンテンツを部分的に手作業によって修正するというような作業を 行うためのものである.そのため,一人の管理者が・全ての情報項目に対して・ 全ての編集操作を行える,ということが機能的要件となっている.
このような管理・編集ツールを用いる作業を行うことは, アプリケーションが利用しているスキーマを 不注意によって破壊してしまうリスクを冒すことにもなる. また,良くも悪くも作業を多人数で分担することが困難である. この結果,データベースは静的な利用目的とスキーマ定義に基づいて, 限定された範囲での運用がなされるものとなっている.
そこで,これらのデータベースコンテンツの管理・編集ツールの 設計モデルについて,動作モデル・権限モデルを マルチユーザ化し,システムを分散オブジェクト基盤の上に 実装することによって分散化をを行う形で 拡張することについて,検討を行った. この拡張を行う上での要件としては,
- ユーザに対する利用環境面でのバリアを下げること
- 複雑に関連したな情報構造を操作・編集するインターフェイスを, 可能な限り単純な形で提供し,ユーザに対する負担を低減すること
が必要であると考えた. 1から,利用クライアントはWebブラウザとし, HTTP1.1/JavaScript1.1などの標準的・基本的な機能のみを 使うこととした.2から,情報項目同士の参照関係の ブラウズ手法の開発と,そうした情報項目の内容や その参照関係の更新の作業を,多ユーザ分散環境から行う場合における, 情報の一貫性保持のための必用条件として抽出した.
以上の設計モデルを Web Structured Data Management Model(Web SDM Model)と名付けて, 今回独自に開発した多ユーザ分散型のコミュニティウェア (データベース機能とそのhttpインターフェイス)の中で提供した. また,この実装を利用してアプリケーション開発を行い, 実地での利用試験を行った.
B-3. Web Structured Data Management Modelについて
Web SDM Modelは, 以下のような特徴を持つものである.
これらWeb SDM Modelの設計上の要点を,プロトタイプシステムの実装作業 によって,検証を行った.
- クライアントとしてWebブラウザを利用するような n層システムとして構成される. ただしプロトタイプとしては, データベースとWebサーバがモノシリックに結合した2層システムとして 実装した.
- データベース内の情報項目間の参照・被参照の構造を, Webのハイパーリンクの形で作成することによって, 関連を双方向的にブラウズする手法を開発した.
- データベース上では, 所有者ごとに利用権限を設定する機能を備えた形でオブジェクト(情報項目)の 格納を行った.
- 多数のクライアントからの並列的アクセスに対応するために, 共有ロック方式での更新トランザクションを行う仕組みを実現した. 具体的には,オブジェクト内容の更新を行う場合に, 更新を実行する事前と事後に, 情報更新の影響が及ぶ可能性があるオブジェクトに対して 更新イベントを通知する仕組みとして, トランザクション機構を実装した.
- オブジェクトの参照・被参照構造をもとにして, 更新トランザクションがコミットされた場合の影響範囲を判定する 仕組みを実現した.これはすなわち, オブジェクトメンバによる参照・被参照構造を, 更新イベントのpublish-subscribe関係と見なして動作させるものである. subscribe側オブジェクトが更新イベントを受けて状態変化をすると, このオブジェクトの変化をsubscribeする別のオブジェクトへと 更新イベントが伝播する. また,この機構をメタオブジェクトのレベルで用いることで, オブジェクトメンバの参照と被参照の情報の対応関係の 一貫性を保証する仕組みを実現している.
- HTTPの一連のセッションの中に,共有ロック方式による 更新トランザクションを盛り込む設計方式について検討し, 更新トランザクションの開始からコミットに至る流れを, ポップアップ式インターフェイスの中でユーザに明示するような形で 実装した.
B-4. プロトタイプシステム
プロトタイプシステムは,Webブラウザをクライアントとした 単純化された構成のパフォーマンスの高いシステムとするために 専用のhttpdとDataBaseとして開発した.
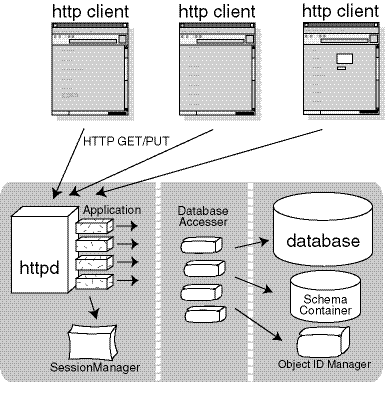
図:Web SDM プロトタイプのシステム構成図プロトタイプシステムは, Web SDM Modelを実装・運用によって検証する基盤として利用した. また,コミュニティによる知識管理(knowledge management)ツール・ CSCWツールとして,実用的な用途に供することも可能であり, いくつかの事例に対して適用を行った.
B-5. システムの構成
- 使用言語:
- Perl 5.004,JDK1.0.4など
- コードサイズ:
- 計約6000行, 260KB
- プロセス構成:
- 1プロセス1スレッド,モノシリック型
B-6. システムの運用に必要なもの
- サーバ側(HTTP1.1サーバ)
- Perl5.004以上
(WindowsNTは不可.GDBMまたBerkeleyDBなどを利用して, 永続ハッシュテーブル機能が組み込まれていること)- クライアント側(HTTP1.1クライアント)
- NetscapeNavigator3.0x/Communicator4.0xを使用. (HTML3.0,JavaScript1.1に準拠すること)
B-7. インターフェイス構成e
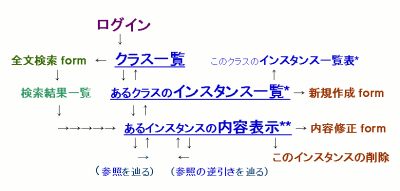
- ログイン:
- Cookieの発行
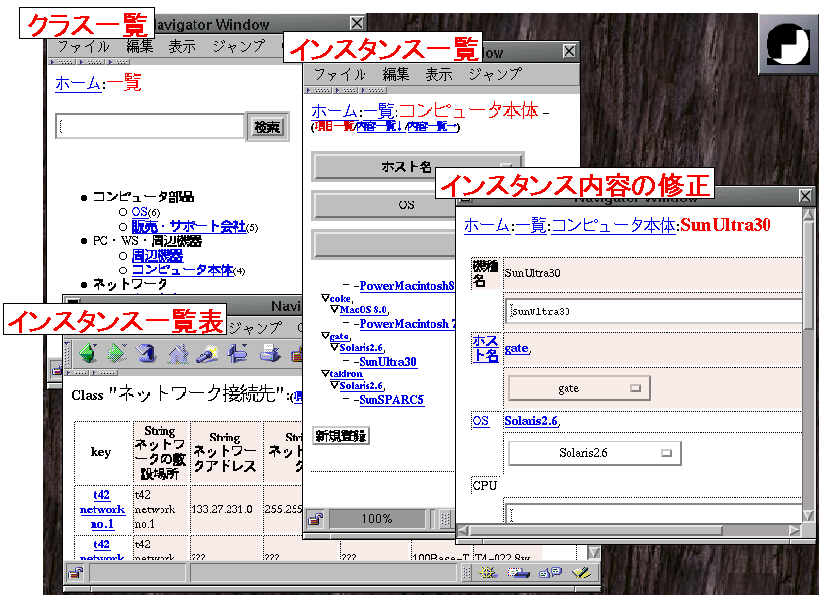
- クラス一覧,インスタンス一覧*,内容表示**:
- ツリー上の階層的なページ構成
- 参照・参照の逆引き:
- ハイパーリンクによってブラウズ可能
- 新規作成,内容修正・削除:
- 新しく開いたウィンドウ内での更新トランザクション
B-8. 利用画面例
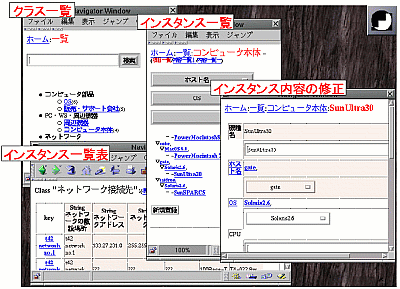
B-9. プロトタイプシステムの応用事例
プロトタイプシステムは, 慶應義塾大学 政策・メディア研究科 金子研究室内における グループウェアとして試験的に利用された.また,株式会社電通 CooperateCommunication局内のイントラネット用システムの一部として 1998年3月から利用されている.
多ユーザそれぞれの役割分担を クラスの権限設定によって作り出すことで, 様々なアプリケーションモデルを実現できる.
また,「逆向きのリンク」を ハイパーリンクとして具体化しユーザに提示することが, アプリケーションの利用目的に即した有意なリンク情報として, 機能することを示した.
グループ内のミーティング日時調整用アプリケーション
グループウェアとしての利用を検討する. 一般に,日程調整は, 電子メールで手作業で行われるか, 特定の日程調整用アプリケーションで行われている. これに対し,Web SDM Modelを用いることで, 単純なスキーマ定義とユーザ属性の付与だけで, 実用上十分な日程調整用アプリケーションが, 他の情報サービスとシームレスな形で実現できた (クラス数4).
- ミーティング開催候補日時クラスを作る管理者が作っておく. 具体的な日時をインスタンスとして作っておく.
- ミーティングの候補日時調整用クラスを管理者が作っておく. それぞれのユーザが,そのインスタンスを作ることによって, 自分が出席可能な日時を示す.
- ミーティング開催候補日時クラスのインスタンスの 逆向きのリンクを調べることによって, それぞれの日時にどのユーザが参加できるかを確認できる.
蔵書管理用アプリケーション
データベースとしての利用を検討する. Web SDM Modelを用いることで, 通常であればリレーショナルデータベースとCGIを利用して 構築するようなWeb上のアプリケーションを, スキーマ定義をするだけで作成できた (クラス数9).
- 表形式の蔵書管理データベースを作っておく.
- 本の貸し出しをする場合には, 貸し出し中クラスのインスタンスを作成し,そこから1. の 本を参照しておく.
- その本が貸し出し中であるかどうかは, 蔵書インスタンスについて逆向きのリンクを調べることによって, 2.を得ることによって確認できる.
- あるユーザが現在どの本を借りているかは, ユーザインスタンスについて逆向きのリンクを調べることによって, 2.を得ることによって確認できる.
アンケート収集用アプリケーション
インターネット上のアプリケーションとしての利用を検討する. このシステムを利用して, 合計200件ほどのアンケートを収集した. 同時に利用するユーザ数がそれほど多くないような用途であれば, インターネット上での利用にも支障がないということが推測された (クラス数14).
- アンケートの質問をクラスとする.質問に対する選択項目をインスタン スとして管理者が作成しておく.
- アンケートをクラスとする.フィールドとして, アンケートの質問を列挙しておく.自由回答の部分は,フィールドをTextを クラスとして定義しておく.
- システムをインターネット向けに匿名ログイン可能なモードで公開す る.
- 匿名ログインしたユーザに,アンケートのインスタンスを作ってもら う.アンケートの性質によって,そのインスタンスは非公開もしくは公開のいずれか を選ぶ.公開の場合には,他人の投稿内容がその場で読めるような形で 情報共有が行われる.
B-10. 評価
他の「多ユーザ分散型情報共有システム」との定性比較により, 本システムの設計モデルについて,多ユーザ分散型の CSCWシステム基盤としての評価を行った.
分散情報リポジトリの設計問題には, 細目に渡って厳密に一貫的な情報システムであろうとすれば 分散システムとしての利用のパフォーマンスを損なうという トレードオフの問題がある. そこで,評価の際の検討項目として, 情報の問い合わせ・情報の取得の単位粒度となる概念の表現方法についてと, 情報の参照・依存状態の表現方法について比較し,このトレードオフ問題 の中でのバランスのさせかたを定性的に分析した. これにより,本システムが目的としている用途への相対的な適用性を 示すことができた.
検討項目:
- 粒度
情報には,「実体」と「コピー」と「参照」の3種類がある. このような意味的な区別を行うためには, すでにある情報の一群のカタマリに対して, 適切なスキーマと操作粒度の定義を持っておく必要がある.
「実体」「コピー」「参照」といった情報を, 一次記憶装置上に乗せきれないような場合には, 二次記憶(またはネットワーク先のマシン)と通信して, それらとの間で情報を出し入れする必要がある. このとき,たとえば, 一次記憶上で扱われるアプリケーション用の個々の情報を, ハードディスクなど二次記憶上に表現されている一般的な 情報の格納単位であるファイル一つに1対1に対応させて 表現する方法では,処理上のオーバーヘッドが大きい. そこで, 一次記憶上の情報と二次記憶上の情報を1対n的に対応させて, 情報の取り出し・格納のためのメッセージのやりとりを 圧縮するという手法が取られる.
このような場合, 一次記憶上の情報と二次記憶上のそれぞれの情報を操作する プログラミングインターフェイスのミスマッチが問題となる.
そこで,API的に,二次記憶上の情報を取り扱う際の 操作の最小単位として提供されている情報粒度についてを検討する.
- 参照
実体と参照との,適切な使い分けがされているかどうかを検討する.
「実体」はグローバルにユニークなものとして, 「コピー」を行わずすべて「参照」するモデルが最も単純である. だが,「実体」への通信の負荷や遅延が大きくなる傾向があり, 広域分散システムには適用しにくい.
そのため,「コピー」を作成しこれを利用する場合がある. このときには,情報の更新を行う場合の手続きとして, 実体とコピー,コピーとコピーの間の情報の整合性を 保持するための,何らかの仕組みを持つことが必要である. しかし,このような情報の整合性の保持の機能については, 設計・実装・運用とも非常に困難であるため, 単に「コピー」を濫用するという形で問題を放置してしまうような 実装が多い.
- 依存関係管理
更新時の矛盾発生を警告する仕組みを持つかどうか.- トランザクション
分散多ユーザによる同時的更新に備えて, 一貫性の保証,可視性の制御,障害回復機能などの 適切な実装を持っているかどうか.- バージョン管理
分散多ユーザによる更新には, アプリケーション的に検出不可能な意味的矛盾・ 間違った更新情報が含まれる場合がある. このような問題の発生に備えて,ある過去の時点の データベース状態に復帰する機能を持つ必要がある.比較対照:
- AFS+RCS
Andrew File System + Revision Control System- CVS
Concurrent Versin System- Web DAV
Web Distributed Authorizing and Versioning- LDAP
Lightweight Directory Access Protocol- RDB
Relational Data Base Management System- Web SDM (本研究プロトタイプ)
Web Structured Data Management
粒度 参照 依存関係 トランザクション バージョン管理 AFS+RCS 粗:file X X X:排他的ロック ○ CVS 粗:file X △:moduleの依存関係の構造化 X:共有ロック ○ WebDAV 粗:file X ○:変更イベントの通知 X:共有ロック ○ LDAP 細:object ○:directoryのリンク △:レプリカ の作成指示 X X RDBMS 細:tuple △:keyによるjoin X ○:排他的ロック X WebSDM 細:object ○:objectID ◎:変更イベント通 知 ○:共有ロック X:future work
B-11. 考察
一般に, ファイルシステムやデータベースなど, 永続的な2次記憶上を基盤として作られるアプリケーションが ユーザに対して提示する情報は, 論理スキーマの外部スキーマから,さらに個々のアプリケーションの 特定の利用目的に応じて表現手法を作り出した,加工済みのものである.
本システムのプロトタイプの設計においては,この逆説的な着想により, 「生のデータベース」をユーザに見せるという手法を採用している. データベース内の情報項目を一般化し, Webブラウザを利用して情報項目同士の関係性をハイパーリンクの形で 表現するという方法で,情報への統一的でバリアの低いアクセスを 行うシステムを実現した. これは,従来のような, 加工済みのデータベースの一部を見せる手法に比べて 「生のデータベース」をユーザに見せるという手法が, 必ずしも非現実的ものではないということを示すものである.
これによって,より一般性・適用性の高いコミュニティウェアを作成することが 可能であると考えた.また実装作業において,その具体的な実現手法を 示すことができた.
また同時に,情報の参照・更新権限の所有や委譲の 機能に基づいた責任分担制度を創発すること, 情報更新における一貫性の問題に着目し トランザクションの概念をユーザに対して 可視的に提示することなど, コミュニティウェアとしてのいくつかの要件を抽出し, これらをシステムの中で利用することについて, それぞれ具体的な実装と運用に基づいて提案を行った.
B-12. まとめと今後の課題
- 「コミュニティ型情報共有モデル」の必要性について論考した.
- 「コミュニティ型情報共有モデル」について,具体的な設計と実装を行った.
- 「コミュニティ型情報共有モデル」を実現する場合には, 情報の一貫的構造を管理するための メタ・ルール(メタ・ロジック)部分の設計が重要であることを示した. これをプロトタイプシステムを実装することによって検証した.
- プロトタイプの実装について:
- 実装 :
- 多ユーザ・分散型で共有されたデータベース内の情報を, 参照関係に基づいて管理するシステムをWebをインターフェイスとして実装した.
- 運用 :
- プロトタイプシステムをいくつかの事例に対して実際に利用を行った.
- 評価 :
- 他の分散情報リポジトリシステムとの間で定性的な比較に基づいた 評価を行った.
- まとめ :
- 情報共有システムの情報管理の複雑性を軽減するには, 参照関係を用いた管理モデルが有効である.
今後はプロトタイプを反映し, 「コミュニティ型情報共有モデル」の本システムの実装を行う. プロトタイプシステムの実装言語としては, インタプリタ型スクリプト言語を利用したわけであるが,, 本システムでは分散オブジェクト・コンポーネント技術を利用して 開発を進めている.これはシステムの自己記述性・再構成性の点で これは,構成の自由度と再利用性を両立させることを意図している. その際の課題を以下に挙げる.
- メタ・ルールに基づいたコンポーネントの動的再構成
- スキーマ動的進化機構
- 一貫性保持のための検査機構の高度化
- オブジェクトの表示・編集インターフェイスの高度化
- 被参照構保持のスケーラビリティへの対応
- 更新のバージョン管理