| 研究概要 |
|
本研究では既存レコメンデーション・エンジンについての問題点を明らかにし、それらの問題点を解決する方法として「データマイニング手法」を適用した手法を提示する。なお分析用データとして実際のビジネスデータ(大型小売店舗におけるPOSデータ・パネルデータ)を用いることにより、包括的かつ実践的なデータマイニング利用法の提示を行った。 |
| 研究目的 |
|
「レコメンデーション」は企業が顧客に対して購買商品を推薦するマーケティング手法であり、企業がレコメンデーションを実行する際には、対象とする顧客をよく理解し、どのような商品・サービスを求めているかを十分に把握する必要がある。現在では、ネットワーク技術やデータベース技術といった高度な情報処理技術を用いることで、顧客個人の購買行動情報やプロファイル情報を蓄積し、それらの情報を分析することによる顧客理解進められており、これらは総じて「データベース・マーケティング」と呼ばれる。 既存レコメンデーション・エンジンでは、主に「協調フィルタリング」と呼ばれる技術を用いて、各顧客の趣向把握および趣向に則した商品の導出を行う。しかしながら、「協調フィルタリング」は各顧客どうしの相関係数をインデクスとしているため、「複雑性の欠如(=商品評価情報以外を含むことができない)」「レコメンデーション結果の解釈が不可能」(以上、Ansari(2000))「商品評価情報がない顧客へのレコメンデーションが不可能」という問題が生じる。 具体的には「コホーネンの自己組織化マップ」を適用した類似顧客セグメントの形成を行う。また同時に、「階層的クラスター分析」「非階層的クラスター分析」などの統計解析手法との比較から、データマイニング手法の効果を測定する。その際、これらの異なる顧客セグメント手法の”良さ”を測定する基準を提示し、各手法のレコメンデーション効果を比較する。 ここで本研究の目的を整理すると次のようになる。 ■レコメンデーション・エンジンの類似顧客発見プロセスにおけるデータマイニング手法の適用 |
|
|
| 活動内容 |
|
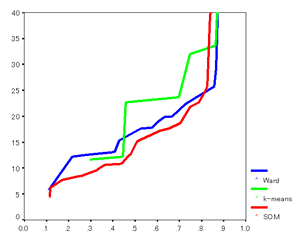
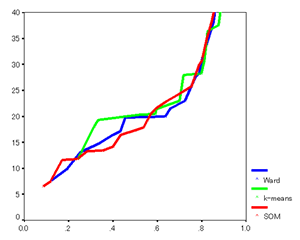
■ 分析環境の構築 ・ハードウェア環境 ・ ソフトウェア環境 ・データ 上記のうちソフトウェアおよびデータについては本プロジェクトで既に所有していた資産であり、本基金は分析用ハードウェアの購入に充てることで分析環境の整備を行った。 ■ 分析プロセス ・所与データによるデータベース構築 ・分析用データの「抽出」「変換」「クリーニング」 ・データマイニング・ツールおよび統計解析ツールを用いた類似顧客セグメント形成 ・各手法における「累積顧客カバー率に対する級内分散」グラフの作成
この2つのグラフから、「コホーネンの自己組織化マップ(赤線)」で他の手法と比較して安定して低い級内分散を得ている。すなわち、コホーネンの自己組織化マップにより形成される顧客セグメントを用いることで、高精度のレコメンデーションを実行することが可能となる。 |
|
|
| 研究成果 |
|
本研究による成果は以下の通りである。 (1)実際のビジネス・データを用いた、実践的なデータマイニング分析プロセスの提示。 そして本研究で提示した「レコメンデーション・エンジンにおける、データマイニング手法による類似顧客発見手法」に加え、「データマイニング手法を適用した、顧客属性情報による所属顧客セグメント発見」を実行すれば、これまでレコメンデーション・エンジンでは実行が不可能であった「購買履歴のない顧客(新規顧客など)へのレコメンデーション」が実行可能となる。よって今後とも継続的な研究が期待される。 なお本研究の成果に関する詳細については、江崎(修士課程2年)による論文にまとめられている。 |
|
|