目的
本研究(概念階層と概念記述の相互学習による漸増学習について)の研究課題は, (1)帰納論理プログラミングを用いた,継続的,自己拡張的なアルゴリズムの 設計・試作,及び(2)その言語獲得,技能獲得への応用である.そこで,帰納 論理プログラミングの理論・システム開発・応用に関して先進的な研究を行っ ている英国York大学 計算機科学科 Stephen Muggleton教授らの研究グループ を訪問し,意見交換及び共同研究を行う.また特に本研究の応用の一つである 「幼児の言語獲得」に関して,必要とされる理論やアルゴリズム,適用可能な 既存技術を検討し,今後の研究の方向性を明確にすることを,主な目的とする.
York大学訪問に次いで, 第17回 Machine Intelligence 国際会議(MI-17) 及び 第10回 Inductive Logic Programming 国際会議 (ILP2000) に参加する.MI-17は,``Life Long Learning and Discovery''に 焦点を当てており,言語獲得や技能獲得などもこれに含まれる. 会議に参加することで,本研究における応用(言語獲得と技能獲得) の更なる可能性について,さまざまな知見が得られることが期待される. またILP2000は,本研究がその基礎としている帰納論理プログラミングに 関する国際会議である.したがって, 本研究の基礎の部分に大きな貢献があると考えられる.
またMI-17, ILP2000ともに,共著論文が発表される.
- MI-17
- Imai,M., Kobayashi,I., Ozaki,T., and Furukawa,K.:
- ``Mechanism of Lexical Development''.
- ILP2000
- Furukawa,K., and Ozaki,T.:
- ``On the Completion of Inverse Entailment for Mutual Recursion and its Application to Self Recursion''.
訪問先
- 英国York大学 Computer Science学部 S.Muggleton教授
- The 17th International Workshop on Machine Intelligence (MI-17).
- The 10th International Conference on Inductive Logic Programming (ILP2000).
日程
| 7/11 | 成田〜ヒースロー(英国) VS901便(11:00発, 16:00着) Yorkへ移動 |
| 7/12 〜18 |
York大学での共同研究
|
| 7/18 | Suffolkへ移動 |
| 7/19 〜21 |
The 17th International Workshop on Machine Intelligence (MI-17) |
| 7/22 | Londonへ移動 |
| 7/24 〜28 |
The 10th International Conference on Inductive Logic Programming (ILP2000) |
| 7/29 | ヒースロー(英国)〜成田 VS900便(13:00発, 09:00(+)着) |
宿泊先
| 7/11〜18 |
The Gables Gest House 50 Boontham Crescent, Bootham York, YO3 7AH |
| 7/18〜22 |
Bury ST EDMUNDS HOUSE Newton Court, Bury St Edmunds, Suffolk, IP29 5LU |
| 7/22〜29 |
Princer's Garden Imperial Colledge Watts Way, Prince's Gardens, South Kensington, London, SW7 1LU |
[TOP]
York大学での共同研究内容及び成果報告
York大学では,主に本研究課題の応用の一つである,「幼児の言語獲得システ ムの構築」に関して研究を行った.以下,帰納論理プログラミング,及び言語 獲得のモデル化について簡単に説明を行う.次いで訪問中に行った,``帰納論 理プログラミングシステムProgolを用いた言語獲得システムの構築に関する検 討''に関して,その詳細を述べる.
(1)帰納論理プログラミングとProgolシステム
帰納論理プログラミング(Inductive Logic Programming, ILP) [4]は, 一階述語論理上の教師付き学習の枠組みであり, 正例(E+),負例(E-),背景知識(BK)が節集合で与えられ, 背景知識だけから正例が説明されないときに,
S.Muggletonらによって開発されたILPシステムProgol [4]は,現在もっとも優れたILPシステムの一つ であり,実際様々な応用に利用されている.Progolは帰納推論の問題を,(1) 正例集合の一つの要素と背景知識から,最弱仮説(Most Specific Hypothesis; MSH)を生成し,(2)MSHによって形成される候補仮説束内をA*-like探索 アルゴリズムに従い探索し,最適な仮説を発見する,(3)得られた仮説によっ て説明される正例を正例集合から取り除く,という処理を,正例集合が空にな るまで繰り返すことで,仮説を生成する(図1).この内 (2)のA*-like探索では,仮説評価のために,仮説によって被覆される事例 の数を計算する.この計算は被覆計算と呼ばれる.また(3)における処理を, 被覆集合アルゴリズムと呼ぶ.
Progolへの入力としては,正例,負例,背景知識の他に,探索空間を限定する 情報として,modeh宣言とmodeb宣言からなる``モード宣言''が与えられる. modeh宣言は,学習すべき概念の定義であり,仮説頭部を規定するものである. またmodeb宣言は,利用する背景知識の定義であり,仮説本体部を規定するも のである.この様にProgolでは,仮説を構成する述語がモード宣言で与えられ ることになる.またシステムの出力は,モード宣言により限定された仮説空間 の探索によって得られる論理プログラムである.

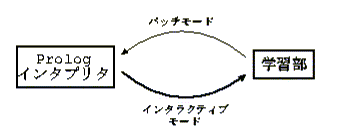
Progolシステムはその内部にPrologインタプリタを実現している.すなわち大 雑把に,(1)演繹推論(deduction)を行うPrologインタプリタと(2)帰納推論 (induction)を行う学習部とからなる(図2).そして, バッチモード(学習に利用するデータを最初に全部与えて学習させる方式)で Progolを実行した場合は,学習部がPrologインタプリタを呼び出し,それを利 用することで学習が進められていく.逆にインタラクティブモード(学習に利 用するデータを対話的に与えて学習させる方式)でProgolを実行した場合は, Prologインタプリタから学習用の組み込み述語を呼び出すことで,対話的に学 習が行われることになる.
(2)言語獲得のモデル化
本研究は,認知科学分野で提案されている幼児の言語獲得に関する種々の``バ イアス''[2]を,機械学習,特に帰納論理プログラミ ングの枠組みでモデル化し,実際の言語獲得過程を計算機上でシミュレートす るというものである.また,言語獲得という表面に現れる現象を再現するだけ に留まらず,シミュレーションを通じて,言語獲得の裏側にある各バイアスの 役割やバイアス間の関係をも明らかにすることを最終的な目標としている.さ らに本研究を通じて,既得知識の利用による漸増的な学習や,状況に合わせた バイアスの選択的な利用などの実現が期待されることから,機械学習システム の観点からみた場合にも,非常に意義のある研究であると言える.
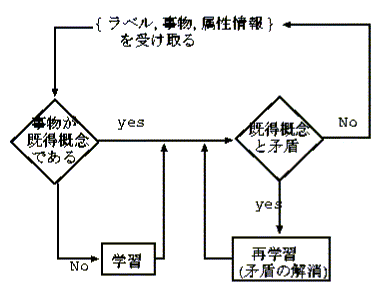
図3に,これまで我々が開発を進めている帰納論理プ ログラミングによる幼児の言語獲得システム [1,3] の概略を示す. まず,システムに対して,「ラベル」と「事物」及びその「属性情報」を与え る.そして一組の入力が与えられる度に,(1)既得概念かどうかのチェックと 無矛盾性のチェック,及び必要に応じて(2)概念の(再)学習と(3)矛盾の解消が 行われる.このとき(1)のチェックは演繹推論の枠組みで,(2)の学習は帰納推 論の枠組みで行われる.さらに帰納推論に関しては,「ラベル」を帰納論理プ ログラミングにおける「クラス」に,「事物」を「事例」に,「属性情報」及 び既得知識を「背景知識」にそれぞれ対応づけることで対処している.また (3)の矛盾解消に関しては,(2)の再学習の他に,認知的バイアスに基づいた概 念階層の導入などが行われる.
(3)Progolによる言語獲得システムの構築
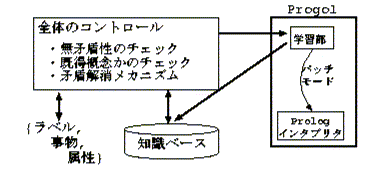
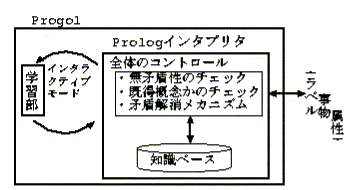
共同研究においては,まず,Progolを用いて言語獲得システムを構築する場合 の基本的なアーキテクチャについての検討が行われた.その過程において, 図4に示す2通りのアーキテクチャが提案され,それぞ れの利点・欠点などが検討された.
アーキテクチャ1
 アーキテクチャ2
アーキテクチャ2
図4:Progolによる言語獲得システムの構成
アーキテクチャ1は,学習部(帰納推論部)にのみProgolを利用する方式である. この方式では,全体を制御するプログラムが,入力情報を読み込み,知識ベー ス(演繹推論部)を参照して無矛盾性などのチェックを行う.そして必要があれ ば,Progolをバッチモードで起動し学習を行う.このアーキテクチャの利点は, 全体を制御するモジュールと,帰納推論を行うモジュール(今回の場合は Progol),及び演繹推論を行うモジュールのそれぞれが独立している点である. 従って,帰納推論,演繹推論それぞれで,より良いアルゴリズムやシステムが 開発された場合,容易にそのアルゴリズムやシステムを導入することが可能で ある.また演繹推論に関しては,より大規模な問題を対象とすることのできる 演繹データベースの利用や,言語獲得で必要となるであろう非単調推論の導入 などが比較的容易にできる.さらに全体を制御するプログラムに関しても,実 装する言語を自由に選択することができるという利点を持つ.
しかしその一方で,このアーキテクチャは,全体を制御するプログラムと演繹 推論モジュール,帰納推論モジュールとのインターフェースを実装する必要が あるという欠点を持つ.全体を制御するプログラムと演繹推論モジュールとの インターフェースは,Prologでの実装を前提とすれば,Prologの知識ベースを 演繹推論モジュールとしてそのまま利用できるので問題はない.しかし帰納推 論モジュール(Progol)とのインターフェースは,Progolシステムをそのまま利 用することを前提とした場合,Progolシステムの構文に沿った入力データ(入 力ファイル)の生成,及びProgolの出力の構文的な解析が必要となる.特にファ イルを通じてのインターフェースを採用する必要があるので,学習が進み,扱 う知識の規模が大きくなった場合,このインターフェースがボトルネックにな ることが容易に想像できる.またProgolシステムを改良し,ファイルを介さな いインターフェースを実装することも考えられるが,その場合,膨大なProgol のソースを解析・理解する必要がある.
アーキテクチャ2は,Progolをインタラクティブモードで起動し,Progolが内 蔵するPrologインタプリタ上で全体を制御するプログラムを動かす,というも のである.すなわち,無矛盾性のチェックなどの演繹推論をProgol内のProlog インタプリタで行い,必要に応じて組込み述語を呼び出すことで学習(帰納推 論)を行う,というものである.これにより,すべての操作がProgolシステム の中だけで行われるという利点を持つ.すなわち,すべての情報のやりとりが Progol内のPrologインタプリタを通じて行われることになるので,特別なイン ターフェースを構築することなく,言語獲得の核となる部分だけに集中して, システム全体の設計・実装が可能となる.
その一方で,このアーキテクチャは,Progolシステムに完全に依存しているの で,帰納推論に関してはProgolの能力を超える範囲のことはできない.また演 繹推論部に関しても,実装する言語はProgol内のProlog言語に限定されるとい う欠点を持つ.
ところで,現在のProgolシステム[5]は,(i)正 例のみ(単一クラス)からの学習が可能である,(ii)確率的な情報が扱える,と いう特徴に加え,言語獲得における認知バイアス実現のために必要不可欠であ る,(iii)枝刈り基準や一貫性制約の導入による探索の制御,(iv)利用者定義 の評価関数の導入が可能である,という他のILPシステムには無い利点を持っ ている.すなわち,Progolは他のILPシステムと比べ,言語獲得システムにお ける帰納推論モジュールとして,非常に適していると言える.またProgolシス テムでは,入出力や知識ベースの更新等も含め,Prologの基本的な機能が提供 されており,演繹推論モジュールとしてみた場合にも問題はない.従って,アー キテクチャ1のように,特に演繹推論モジュールと帰納推論モジュールとを独 立に設計・実装するまでもなく,Progol上のPrologを利用し,すべてのプログ ラムを実装した方が,簡便かつ見通しが良いとの理由から,今回の共同研究で はアーキテクチャ2を採用することとした.
次に,Progolを用いた言語獲得システムを実装する上で,特に重要となる技術 的な問題について示す.
- モード宣言及び事例の生成:
-
Progolを利用して学習(帰納推論)を行う場合には,予めモード宣言を設定する
必要がある.しかし現在のProgolにおいては,どのようなモード宣言が既に宣
言されているのかを直接参照する機構が提供されていない.そこで学習前に知
識ベースを参照し,これまでに現れていないラベル及び属性情報に対して,そ
れぞれmodeh宣言,modeb宣言を自動的に作る機構を実現する必要がある.
- また通常の帰納推論とは異なり,言語獲得においては,各ラベルに関する負例 が明示的に与えられることは期待できない.従って,何らかの方法でラベルに 対する負例を設定する必要がある.この問題に対して我々はこれまでに,``階 層関係''の利用と``類似度''の利用による,(正)負例の生成方式を提案してい る.この提案手法に基づき,必要に応じて適切な正例,負例を生成・登録する 機構を実現する必要がある.
- 評価関数の設定:
- Progolは,デフォルトでは記述長最小原理に基づいた概念(仮説)の評価基準を 利用している.これに対し,言語獲得システムでは,認知バイアスに基づいた 概念の評価基準を採用する必要がある.さらに将来的には, 学習の進行に合 わせてこの評価関数自体を変化させる操作が必要となる.また一般に,評価関 数が決まらないと,枝刈り基準などが定まらず,結果として効率的な学習がで きないという問題がある.これに対し,近年 S.Muggleton によって,より一 般的な利用者定義の評価関数の設定の方法,及びそれに基づく枝刈り基準の導 入に関する研究 [5] がなされており,今回この研究成果を利 用することを検討している.これにより,利用者の側で,動的に変換する評価 関数を設定したとしても,かなり効率の良い学習を行うことが可能となると考 えている.
今回の共同研究では,Progolを用いた言語獲得システムの構築に関し,そのアー キテクチャ,及び必要とされる技術的な問題を明らかにし,プロトタイプシス テムの実装を開始した.また今後の課題としては,実際にシステムの完成とシ ステムを使った実験,及び認知実験などとの比較による,システムの評価や認 知バイアスに対する検討などがあげられる.
参考文献
-
Furukawa, K., Kobayashi, I., Ozaki, T., and Imai, M.
A Model of Children's Vocabulary Acquisition Using Inductive Logic Programming,
In S.Arikawa and K.Furukawa (eds.), Proc. of the Second International Conference on Discovery Science (DS99), 1999.- 今井むつみ,
「言葉の学習のパラドックス」,
共立出版,1997.- Imai,M., Kobayashi,I., Ozaki,T., and Furukawa,K.
Mechanism of Lexicl Development, In Proc. of The Seventeenth International Workshop on Machine Intelligence, pp.32-35,2000.- Muggleton, S.
Inverse entailment and Progol,
New Generation Computing, 13:245-286,1995.- Muggleton, S.
Learning Stochastic Logic Programs, In Proc. of workshop on Learning Statistical Models from Relatonal Data, AAAI, 2000. - 今井むつみ,
[TOP]
MI-17会議報告
第17回 Machine Intelligence 国際会議(MI-17)は,7月19日から21日まで,英 国SuffolkにあるBury St Edmunds Houseで開催された.会議には,機械学習分 野を中心に著名な研究者が多数出席し,理論から,実装,応用まで幅広い内容 で,9つのセッション,25の発表が行われた.
以下,共著論文,及び特に興味深かった発表に関して,その概要を示す.
- ``Imai,M., Kobayashi,I., Ozaki,T., and Furukawa,K.: Mechanism of Lexicl Development. (共著論文)''
- まず幼児の言語獲得という問題に対して,発達心理学,認知科学分野での実験 より提案された,言語獲得における``バイアス''についての説明が行われた. 次いで現在開発を行っている,帰納論理プログラミングに基づく幼児の言語獲 得のモデル化に関して発表が行われた.これは認知科学分野で提案されている 言語獲得に関する種々のバイアスを,機械学習の枠組みで実現しようとするも のであり,単に言語獲得過程を模倣するだけではなく,バイアス間の関係をも 明らかにすることを目的としている.この発表に対し,学習者,すなわち幼児 のバイアスだけではなく,教師,すなわち親のバイアスをも考える必要がある のではないか,というコメントが出された.
- ``Bain,M., and Sammut,C.:Perpetual Learning.''
- 従来の機械学習アルゴリズムは,最初に与えられた問題に対してのみ学習を行 うというものである.これに対し,この発表では新たな情報が入ってくるたび に学習を繰り返し行う,という枠組みが提案された.すなわち学習するエージェ ントを考え,そのエージェントの基本的なアーキテクチャを示すものであった. また必要とされる技術として,帰納論理プログラミング(ILP)や特に理論精錬 (Theory Rivision)があげられた.さらに非単調論理との関係についても述べ られていた.
- ``Furukawa,K., Ueno,K., and Bain, M.: Motor Skill as Dynamic Constraint Satisfaction.''
- 人間の知的活動の一つとしてモータスキルがあげられる.この発表では,モー タスキルの例として特に弦楽器の演奏を取り上げ,筋肉の利用法や姿勢に着目 して行われている研究についての紹介がなされた.モータスキルの獲得を制約 充足問題,特に動的な制約充足問題として定式化している点が興味深い.また このことを裏付けるデータとして,プロと素人を対象に行われた実験結果につ いても報告があった.
- ``Kersting,K, and De Raedt,L.: Bayesian Logic Programs.''
- これまでに,一階述語論理とベイジアンネットワークとを組み合わせる試みが いくつかの提案されている.この発表では,Ngoらによる一階述語論理とベイ ジアンネットワークとの組み合わせを,より簡略化し再定式化したベイジアン 論理プログラム(Bayesian Logic Programs)と呼ばれる新たな言語が提案され た.ベイジアン論理プログラムは,従来の言語と比較し,同じ知識をより簡潔 に記述することが可能であるという特徴を持つ.またPrologのメタインタプリ タを利用した実装についても簡単に紹介があった.さらに,ベイジアン論理プ ログラムの学習についても,その方向性が示された.
- ``Kudenko,D.: Ontology-Based Constructive Induction.''
- 現在の構成的帰納推論は,新たな属性を生成・拡張するのに,あらかじめ十分 な属性情報が得られていることを仮定している.したがって,最初に与えられ た属性集合が不適切な場合,既存の構成的帰納推論の枠組みでは,良い結果を 得ることができない.これに対し,この発表では,いきなり属性集合や表現を 決めるのではなく,中間的な処理としてオントロジを利用することを提案して いる.また,この手法をDNAの分類問題に適用した例が紹介された.
- ``Muggleton,S.: Learning Stochastic Logic Programs.''
- 確率が付加されている論理プログラム,Stochastic Logic Programming(SLP) を例から学習させるという発表.SLPは,論理に確率を付加したもので,より 柔軟な表現が可能であるという特徴を持つ.これまでに確率が付加された論理 プログラムの学習と言うと,構造すなわち論理の部分が予め与えられ,確率の 部分だけを学習するものであった.すなわち,確率というパラメタの学習であ る.これに対し,この発表では,パラメタの学習だけではなく,構造自体も事 例から学習すると言う,非常に挑戦的な枠組みが提案された.具体的には,従 来のILPで構造を,そしてその後パラメタ学習により確率を学習することで, 事例からSLPを獲得するというものである.またいくつかの実験結果も併せて 報告された.
- ``Turcotte,M., Muggelton,S., and Sternberg,M.J.E.: Learning Protein Structure Principles.''
- これまでにILPによるタンパク質の構造の特徴抽出に関する研究が行われてい る.この発表では,これらの結果を踏まえ,様々な背景知識の基で得られる結 果についての比較が行われた.また,背景知識にタンパク質の位相に関する情 報を入れることで,より良い結果が得られることが示された.
- ``Sato,T. Program Extraction from Quantified Decision Trees.''
- ILPの学習アルゴリズムとして大きく集合被覆法(covering approach)と分割統 治法(divide-and-conquer approach)の2つがあげられる.この発表は,後者の 枠組みで論理プログラムを獲得するというものである.トップダウン探索の枠 組みで,論理プログラムを表す限量子つきの木構造を獲得することで,論理プ ログラムの合成に成功している.より具体的には,(1)限量子つきの木構造を 得る,(2)木構造を一階述語論理式に変換する,(3)得られた一階述語論理式を Prologの形式に変換する,という手順をとる.一般に,集合被覆法より分割統 治法の方が学習時間が短くて済むということが言われており,この枠組みは, ILPの実行効率の改善にもつながるものであると考えられる.
[TOP]
ILP2000会議報告
第10回 Inductive Logic Programming 国際会議(ILP2000)は,7月24日から7月 28日まで,英国LondonにあるImperial Collegeで開催された.会議には,帰納 論理プログラミングの著名な研究者が一同に会し,7つのセッション(うち2つ はポスターセッション)で35の発表(うち20はポスター)が行われ,本分野に関 係する様々な議論が行われた.また本会議は第1回 Computational Logic 国際 会議(CL2000)と併設で行われ,1つのKey Note 講演,7つの招待講演,12のチュー トリアルが行われた.
会議全体としては,例年と比較し応用に関する論文が減り,逆に実行効率に関 する論文,理論に関する論文が数多く見受けられた.以下,共著論文,及び特 に興味深かった発表に関して,その概要を示す.
- ``Furukawa,K., and Ozaki,T.: On the Completion of Inverse Entailment for Mutual Recursion and its Application to Self Recursion. (共著論文)''
- 帰納論理プログラミング(Inductive Logic Programming, ILP)における推論方 式の一つとして逆伴意法があげられる.本発表は背景知識をホーン節,事例を 基礎アトム,事例の述語と仮説頭部の述語が同一の場合の,逆伴意法の完全性 及び健全性に関するものである.逆伴意法の完全化に関しては,これまでいく つかの研究が行われてきたが,本発表はより実現的な側面からのアプローチで ある点で,他の研究と異なる.また本研究は特に再帰プログラムの合成という 観点からの貢献も期待されている.
- ``Page,D.: ILP:Just Do It. (Invited Paper)''
- ILPのいくつかの応用例を取り上げ,構造を持ったデータを扱うことのできる ILPの利点が強調された.次いで,今後のILP研究の方向性として,(1)確率を 伴う表現・推論機構の導入,(2)仮説空間の確率的な探索,(3)対象となる問題 に特化したアルゴリズムの開発,(4)人間とのインタラクション,(5)システム の並列化,の5点をあげ,それぞれについての説明が行われた.特に(1)の確率 的な表現・推論機構の導入は,現在最も注目を集めているトピックであり,最 新の研究成果が紹介されるとともに,更なる研究の必要性が強調されていた. また(2),(5)はILPの欠点である実行効率の改善に必要不可欠なトピックであり, 理論だけではなく実装や応用の重要性が改めて示されていた.
- ``De Raedt,L.: A Logical Database Mining Query Language.''
- RDM(Relational Database Mining)という,関係データを対象としたデータマ イニングの新たな言語の提案.これまでにも,SQLなどを拡張する形でいくつ かのマイニングのための言語が提案されているが,今回の提案は,関係データ を対象としている点で特に新規性が高いものであると考えられる.またRDMの Primitiveとして,Generality, Frequency, Dataset, Coverage, Max(Min)を 準備しており,制約論理プログラムと同様に,宣言的にマイニングのタスクを 記述することが可能となっている.また相関ルール獲得や,集合被覆法による ルール獲得に関する具体的な記述を通じて,言語としての特徴が示された.し かし実装は行われておらず,ヴァージョン空間(version space)と,階層的探 索(levelwise-search)アルゴリズムの併用に関するアイディアを示すにとどまっ た.
- ``Kirsten,M., and Wrobel,S.: Extending K-Means Clustering to First-Order Representations.''
- K-Meansによるクラスタリングを,一階述語論理上で展開するという発表であ る.これまでに一階述語論理上でのクラスタリングに関して,いくつかの提案 がなされているが,K-Meansを利用した発表は初めてであった.K-Meansでは, クラスタの中心を求める必要があるが,その手法としてK-medoidsと K-prototypesと呼ばれる2つの手法を提案している.前者は与えられた事例の 中からクラスタの中心を選択すると言う手法であり,後者はクラスタの中心と なる事例を新たに生成すると言う手法である.後者の方がより良い精度でクラ スタリングが行われることが期待されたが,実験の結果は前者の方が良い結果 となっている.これに関して,クラスタの中心の作り方に関して更なる工夫が 必要であると言うコメントが,著者から行われた.また一階述語論理上での具 体的な距離計算は,既存の成果(RIBL2)を利用している.
- ``Muggleton,S., and Bryant,C.: Theory Completion Using Inverse Entailment.''
- TCIE(Theory Completion using Inverse Entailment)というILPの新たな理論 に関する発表.これまでの学習の枠組みは,OPL(Observation Predicate Learning),すなわち,観測された事例と同じ述語を頭部に持つ仮説を得ると 言うものであったが,TCIEでは,観測された事例とは別の述語を頭部に持つ仮 説を学習する.これは,発想推論(Abduction)と帰納推論(Induction)を統合し た学習の枠組みであり,大雑把には,観測された事例から,その背後にあるで あろう関係を得るというものである.すなわち,これまでの学習方式では得ら れない種類の仮説を得ることができるという点で優れている.またProgol5.0 というシステムを利用したいくつかの実験結果が示された.その際の実装の方 式としては,PTTP(Prolog Technology Theorem Prover)が用いられているが, SOLDRやCMGTPの枠組みでも同様なことが実現できると思われる.
- ``Ohwada,H., Nishiyama,H., and Mizoguchi,F.: Concurrent Execution of Optimal Hypothesis Search for Inverse Entailment.''
- 並列化を行うことで,ILPの問題の一つである実行効率を改善するという発表. ILPの並列化の方法として,(1)データを分割する,(2)探索を並列に行う, (3)Class毎に仮説を得る,の3つの方法が考えられるが,この論文では,この うち特に(2)に焦点を当てている.具体的には,探索におけるOPENリストの半 分を,他のCPUエレメントに分配(Dispatch)するという方式で並列化が行われ ることになる.またDispatch自体は,各プロセスが行うが,各プロセスの結果 を他のプロセスに通知するのは,マスタを置いて一括管理で行っている.また 10台のマシンを使った実験結果が報告された.
- ``Sakama,C.: Inverse Entailment in Nonmonotonic Logic Programs.''
- ILPの推論方式の1つに逆伴意法と呼ばれる推論方式がある.この発表は,逆伴 意法をNAF(Negation as Failure)を伴う論理プログラム,すなわちノーマル論 理プログラム(Normal Logic Program,NLP)への拡張するというものである.逆 伴意法は,NAFを伴わない論理プログラムを対象とし,その推論の基礎を演繹 定理(Deduction Theorem)と対偶(Contra Positive)に置いている.しかし, NLPにおいては,この両者は成り立たない.そこで,NLP上で,この両者に対応 する定理を提案し,(制限された)NLP上での逆伴意法を提案している.論理 的な裏づけに基づき,扱える問題クラスが広がったという意味で,非常に重要 な研究であると言える.
- ``Tamaddoni-Nezhad,A., and Muggleton,S.: Searching the Subsumpition Lattice by a Genetic Algorithm.''
- システムの高速化のために,ILPと遺伝アルゴリズム(GA)を結合するという発 表.具体的には,ILPにおける仮説束内の探索にGAを用いると言うものである. 逆伴意法により構成される仮説束内だけを対象とすることで,変数の束縛情報 をあらわす簡単なビットのマトリックスだけで,各仮説が表現できるという特 徴を持つ.さらに,2つのビットマトリックス(すなわち2つの仮説)のAND,OR をとることで,包摂関係における仮説の特化,汎化が行えるという利点を持つ. またこの操作はILPにおける基本操作lgg,mgiに対応している.一方,GAを利 用した場合終了条件をどのように設定するかと言うことが常に問題となる.こ の発表でも終了条件に関しては明確な解が得られておらず,今後のさらなる研 究が必要とされる.
[TOP]