2001年度 森泰吉郎記念研究振興基金 報告書
研究課題名:視聴質調査サイトにおける自由回答文の自動解析の研究
慶應義塾大学大学院政策メディア研究科修士1年:長島 英樹
1.視聴質調査サイト「リサーチQ」の概要
テレビ番組には、視聴率という評価尺度がある。視聴率は視聴の量を測る指標である。これに対して、番組の価値を測る指標として、視聴の質を表す評価尺度が必要であることはこれまでも言われてきていた。「リサーチQ」は、1997年4月に開始された、熊坂研究室とテレビ朝日マーケティング部との共同プロジェクトであり、視聴の質を測るためのアンケート調査をWeb上で実施するものである。この「リサーチQ」は、開始されて以降、5年間で200万件以上のアクセスがあり、1日あたり平均906名(2001年4月以降)の回答者が訪れるサイトである。ここで集められた視聴質データは様々な形で解析され、番組運営に役立てられている。
2.「リサーチQ」のアンケート調査
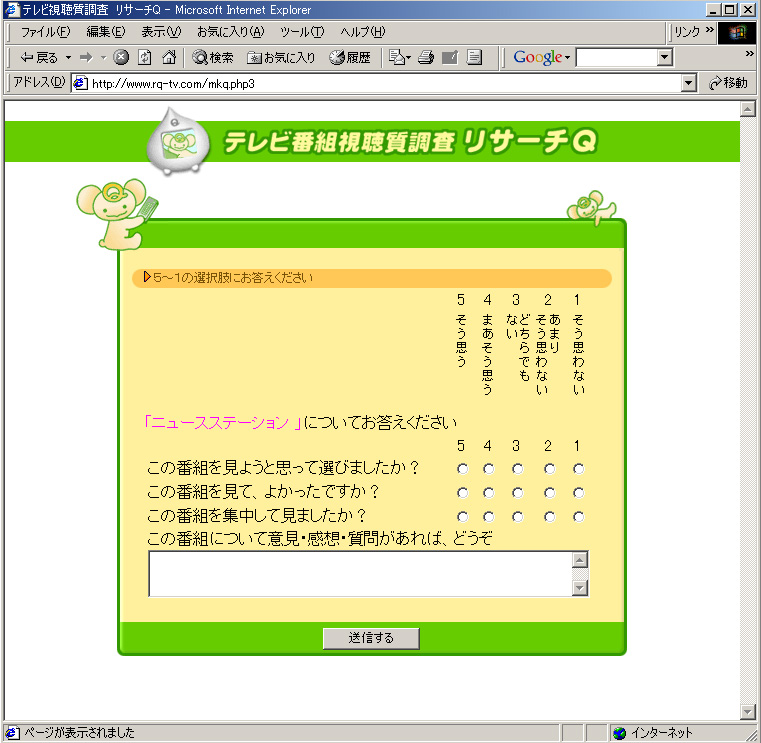
「リサーチQ」のアンケートは、まず回答者が日々の番組表の中から自分が視聴した番組を選び、その後、選んだ番組のアンケート調査に答えるというものである。このアンケートは、以下の3つの質問文からなる。
・この番組を見ようと思って選びましたか?
・この番組を見て、よかったですか?
・この番組を集中して見ましたか?
これらの質問は、それぞれ「期待度」「満足度」「集中度」という、視聴質を表す3つの評価尺度となる。各質問に対して、回答者は「そう思う」「まあそう思う」「どちらでもない」「あまりそう思わない」「そう思わない」の5段階で評価し、これが定量データとして番組の放送ごとにデータベースに保存されている。
また、これらの質問文と同時に、「リサーチQ」では、番組に対する意見や感想、質問などを自由に文章で記述する欄があり、この自由回答文を定性データとして取得している。本研究では、この自由回答文のデータを用いて自動解析を行い、番組の質や視聴者が求めるものが何かなど、制作側に有益な情報を得られるようにすることを目的として進められた。
リサーチQアンケート回答ページ
3.回答者の構成
回答者の性・年齢別構成は、13〜49歳が96%を占め、中でもM1(男20〜34歳)、F1(女20〜34歳)と呼ばれる、番組制作者、広告主共に、最も重要視している世代が、半数以上を占めている。男女比はほぼ半々で、インターネットユーザー全体の比率と比べ、女性がやや多くなっている。
当初、インターネットユーザーによる回答のため、代表性について疑問が持たれていたが、テレビ朝日系列で行っている全国規模の「アトラス調査」の結果に比較しての検証などから、同一の性年齢構成で行った一般の調査と差のないデータが得られることが明らかになっている。
4.「リサーチQ」での解析
「リサーチQ」のアンケートで得られたデータからは、番組間の比較分析であるパターン分析と、番組内の時系列分析であるプロセス分析の2種類の分析が行える。熊坂研究室では、この2種類の分析を、定量データ解析、定性データ解析のそれぞれの解析方法で行っている。前者は主に、番組・コーナー視聴率の先行予測モデルとして、後者は、各番組が放送ごとに、どのように思われ、どのような点に注目されているかを知るための解析として用いられている。本研究では、後者の定性データの部分の解析を行ったのであるが、その報告の前に、その前提となる定量データの解析結果について述べていきたい。
4−1.定量データ解析
視聴質調査の評価尺度として用いられる期待度と満足度は、視聴態度を評価する尺度である。期待度はその番組に期待していたかどうかという、長期的な事前評価尺度であり、満足度は番組を視聴してどうであったかという、短期的な事後評価尺度であるため、それぞれ別の視聴態度を表す指標である。そのため、期待度・満足度の値と差分を比較することで、視聴者の番組・コーナーに対する時系列的な比較ができるようになる。これは、ただ期待度・満足度の定量的な大小で比較するだけの評価方法より、より視聴者の心理に密接した分析ができることを意味する。
ある番組が、期待度が高く、満足度も高ければそれは「期待通り」となる。逆に期待度も満足度も低ければ「予想通り」となる。期待度が高く、満足度が低ければ、それは「期待外れ」となり、期待度が低く、満足度が高ければ「予想外れ」という視聴者の意表を突く番組であったとなる。これらの指標は、その後の期待度・満足度の上がり下がりによって、「期待外れ」「予想外れ」という不安定軸から、「期待通り」「予定通り」という安定軸にシフトする。このシフトの様子を分析することで、その番組の今後の視聴率を予測することができるのである。
実際に、この指標を用いて過去の番組の視聴率の経過の分析を行ったところ、期待度が高く満足度が低い「期待外れ」の番組は、視聴率が下がり「予想通り」で安定し、期待度が低く満足度が高い「予想外れ」の番組は、その後視聴率が上がり「期待通り」で安定することがわかった。この結果から、特にドラマについて言えば、3回目の放送までのデータを用いることで、その後の視聴率の予測ができることがわかった。現在は、各番組の期待度・満足度と視聴率の推移のデータを推移の様子ごとに分類して蓄積し、今後の番組の指標として用いるための研究を行っている。
また、「リサーチQ」では、回答者に、年齢・性別、テレビの視聴時間から趣味や小遣い額まで、さまざまな項目について質問し、これを視聴者属性として保存し、解析をしている。その一例を挙げると、例えば音楽番組を視聴していても、各音楽番組によってCDの購買意欲が高い番組と低い番組があることが、視聴者属性データから明らかとなった。視聴者属性データにより、視聴者の興味の対象やライフスタイル等を明らかにすることができ、それぞれの番組制作者、広告主にフィードバックすることで、番組運営に役立てられている。
4−2.定性データ解析
期待度・満足度などの定量データは、従来からプログラムや表計算ソフトを利用して自動的に集計が行われ、分析されていたが、自由回答文については、集計から分析まですべてが人間の手によって行われていた。その理由は、当然のことながら、コンピュータに文章を理解させることが困難であったからである。従って、「リサーチQ」で回答された自由回答文は、従来までは各番組ごとに手作業によりまとめられ要約され、各番組制作者に伝えられていた。しかもこれは特定の番組に限った話である。手作業であるため、すべての番組についてこれを行うわけにはいかず、その他の番組の自由回答文は、ただデータとして蓄積されていただけであった。
熊坂研究室では、以前から、毎日コンスタントにデータベースに蓄積されるこの大量の自由回答文を自動的に解析するための研究を行っていた。そこで作られたものが、形態素解析ソフト「茶筅」を利用した解析プログラム、「Impression
Extraction System」(以下IES)である。本研究は、このIESの問題点と課題を解決し、これを改良して、より質の高い自動解析を行えるようにするところから始まった。次章では、このIESについて述べていきたい。
5.IESの概要
手作業による要約分析は時間と労力がかかるというデメリットがある。自動解析により即時的処理が可能となるが、手作業による要約ほど高度ではない。(例えば文章化されない点など)この点では出力結果から元の自由回答文を参照できるような支援システムと成り得るような設計となっている。
IESは自由回答文の集合を入力とし、次に、3形式の出力を行う。
1.「プラス表現」「マイナス表現」の出現率
2.「印象語群」とその件数
3.「関連後(印象語群に関係する名詞)」
これらは相互に関係がある。「面白い、おもしろい、愉快、楽しい」というように表記は異なるが似たような意味内容の語の集合を印象語群と呼ぶ。番組にとって良い意味合いを「プラス表現」、悪い意味合いを「マイナス表現」と呼ぶ。「関連語(印象語群に関係する名詞)とは、文に出現した印象語と関係しているであろう語のことを指す。
上記3つの出力形式は、ユーザが得られるものとして、以下のように言い換えることができる。
ユーザは本システムを用いることによって、
1.まずプラスの印象語とマイナスの印象後の出現率により、数値的なデータを得ることができ、
2.またどのような印象後が含まれているのかを俯瞰でき、
3.印象語と関係している言葉がどのようなものかを知ることができる。
実現方法の概略は次のとおりである。既存の形態素解析システムにより文中の形態素情報を得て、その結果を手掛かりに文を関連のあるフレーズごとにリスト化する。抽出したい「印象語」があらかじめ辞書データに格納されており、リスト化されたデータに照合させて情報を抽出する。さらに印象後の出現率を、プラス表現とマイナス表現に分けてそれぞれ計算する。
5−1.印象語辞書
まず、番組にとって良い意味合い、悪い意味合いのを表す言葉を「印象語」とし、印象語辞書を作成した。この印象語辞書はIESの中では3つの役割を持っている。
・抽出のための役割
・良い意味合いと悪い意味合いの区別のための役割
・グルーピングのための役割
IESはまず、自由回答文の中から番組にとって関係のある印象語を抽出する。そして、それぞれの印象語が、番組にとって「良い意味合い」であるか、「悪い意味合い」であるかを判断する。そのため、各印象語には「+1」「-1」「0」のいずれかが記述されている。さらに、抽出された印象語の中で意味の近い印象語をグルーピングする。例えば、「良い」「よい」「いい」「善い」「好い」は表記の違いがあっても意味の違いが小さい。そこでこれらの印象語を同じ意味としてグルーピングするのである。また、「良い」の否定形である「良くない」を「良い」の反意語である「悪い」と同意であるとグルーピングすることも印象語辞書では行っている。
なお、この印象語辞書は、情報処理振興事業協会技術センターによる計算機用辞書「計算機用日本語基本形容詞IPAL(Basic Adjectives)」に記載されている同義語、類義語、反義語などを元にグルーピングが行われ、また同辞書の各語の評価快不快項目により「+1」「-1」「0」の記述が行われている。
5−2.IESの処理内容
IESでは、形態素解析ソフト「茶筅」を用いて、自由回答文を文の最小単位の要素である形態素に分割する。この形態素を作成した印象語辞書にかけ、それぞれの回答文の「プラス表現」「マイナス表現」の数をカウントする。その際に、辞書とマッチした印象語の直前に存在する名詞を抽出することで、擬似的に構文解析までを行っている。これにより、例えば印象語が「おもしろい」であれば、何がおもしろいのかが明らかになる。
また、IESでは自由回答文の中の「〜してほしい」というような「プラス表現」でも「マイナス表現」でもない文章については、要望文として扱えるようになっている。この要望文の判定は、自由回答文の中に「〜ほしい」「〜たい」「もう少し」「〜ください」などの形態素が入っている際に行われる。
5−3.IESの出力形式
以上のように解析された結果を、IESでは、コマンドラインによる実行の他、Webブラウザからの実行も可能にしている。さらに、「リサーチQ」のデータベースと同期を取り、毎日蓄積される回答データにリアルタイムに接続して解析ができるように設計した。この出力は以下の図のようになる。
5−4.IESの評価と考察
IESにより、手作業で行われていた自由回答の集計と分析のうち、集計の自動化に関しては大きな効果をあげた。それまでは手作業で数えていたフレーズを自動的に数えられるようになったからである。また、分析の自動化についても、印象語辞書を用いることで、各番組ごとに定量的に評価ができるようになり、その番組が良いのか悪いのかを知る指標の一つとして、大きく前進したと言える。
5−5.IESの課題と解決策
しかし、IESにもいくつかの問題点がある。まず、インターフェースが悪いということである。解析したい番組を選択する際に、まず日付を選び、その後番組一覧から解析したい番組をチェックして、ようやくその番組の解析が始まる。始めに番組名を入力して結果を表示したり、ジャンルごとに表示させたりなどが出来ないため、使い勝手が悪い。また表示される自由回答も読みづらい。こういったインターフェースの悪さが解析の質を落としていると言える。
また、このIESは構文解析を擬似的にしか行っていない点も問題点の一つである。さらに、この印象語辞書のプラス・マイナス表現が恣意的に分類されていて、ある言葉が文脈によって意味を変化させる場合があることが考慮されていない点も挙げられる。例を挙げれば、ある番組でA、Bというコーナーがあるとした時、
例文1:「Aはおもしろかったが、Bがつまらなく途中で飽きてしまった。」
例文2:「Aがくだらなくて、笑いながら見てしまった。」
といった自由回答文が寄せられたとする。例文1の場合、文意としては否定的なものであるが、「おもしろい」というフレーズがあるため、プラス表現にもカウントされてしまうのである。構文解析を行えば、「Aはおもしろい」「Bがつまらない」「途中で飽きた」の3文に分けられ、その文が最終的に肯定なのか否定なのかが判明すると同時に、具体的にどのコーナーがおもしろく、どのコーナーがつまらないかが分析できるようになるのである。また例文2の場合、文意としては今度は肯定的である。が、「くだらない」というフレーズが恣意的に印象語辞書にマイナス表現として登録されているため、この回答はマイナス表現として分析されてしまうのである。「くだらない」というフレーズは、ドラマやニュース番組ではマイナス的イメージであるが、バラエティ番組であればプラスのイメージになることもあり得るのである。これは、構文解析と共に意味解析を行わなければ解析しきれない部分である。
以上のIESの問題点を踏まえて、昨年夏、IESのニューバージョンを作成した。
6.IES Ver.2
IES Ver.2の大きな変更点としては、まず、インターフェースの進化が挙げられる。解析番組選択時に、前バージョンでは日付入力を行い、その後、番組選択を行うというものであったが、これを、番組名、放送年月日、放送クール、ジャンルで選べるように変更した。さらに、番組名は、番組名そのものでなく、一部であっても指定できるようになった。このことで、解析の際に他番組との比較がしやすくなった。ジャンルや同クールの番組が一覧で表示されるようになったため、解析がスムーズに行われるようになった。
次に、変更点として、関連語の自動的な色づけ機能の実装が挙げられる。番組選択後、形態素のランキングが表示されるが、そこでその形態素のフリーアンサーをクリックすることで、その形態素が使われている自由回答が一覧で表示される。その際に、その形態素が青色に色づけされ、さらに、その形態素の関連語が赤色に自動で色づけされるようになった。関連語とは、動詞や形容詞の直前の助詞を調べ、その助詞の前の名詞で、これをまず関連語とする。さらに、その名詞の前にまた助詞がある場合には、さらにさかのぼって関連語に含めるようにした。これらの関連語を自動的に見つけ、色づけすることで、解析者が見やすく、さらに解析が行いやすくなった。
また、システム面においても、前バージョンとは変化している。前バージョンはデータベースにPostgresを利用していたのだが、これがOracleに変わったため、IES Ver.2もOracleを利用するように変更した。これに伴い、プログラミング言語もPerlを利用していたものをPHPに切り替えた。解析方法についても、前バージョンではあらかじめすべてのフリーアンサーを茶筅を利用して形態素解析し、それを再びデータベースに保存していたのであるが、これを指定するたびに茶筅を起動するように変更した。これにより、新しいデータが入った場合に、新たな作業なしに解析が行えるようになった。
以上がIES Ver.2の主な改善点である。これを元に、さらに解析の自動化を試みるために様々な方法を行った。次章で、その解析方法を紹介するとともに、その可能性について述べたい。
7.「リサーチQ」のこれから
IES Ver.2を作成し、形態素のランキングや、関連語の抽出とそのランキングなど、多くの機能が実装されてきたのであるが、しかし、これだけでは解析としては不十分であると感じた。やはり、今のままではどういった視聴者がどういった番組をどのように視聴しているのかを把握するのは最終的には人の手によるものであるからである。これを改善すべく、形態素の自動解析だけでなく、この部分も自動で解析を行えるようにすることを目標に掲げて、まずは市販の解析ソフトを利用して解析を行ってみた。
SPSS社のClementineを利用し、各形態素の割合のデータをKohonenにかけて、番組のクラスタリングを行うことを試みた。データは2001年の10-12月に放送された続き物のドラマ24番組に限って行った。クラスタ数を様々に変えて何度も実行してみたのであるが、3,4クラスタだとあまりしっくり来る結果とならなかったので、近いドラマは近くに配置されるだろうKohonenの特性を考えて5×5の次元を作り、その配置でクラスタ化を考えることとした。その結果が以下のようになった。
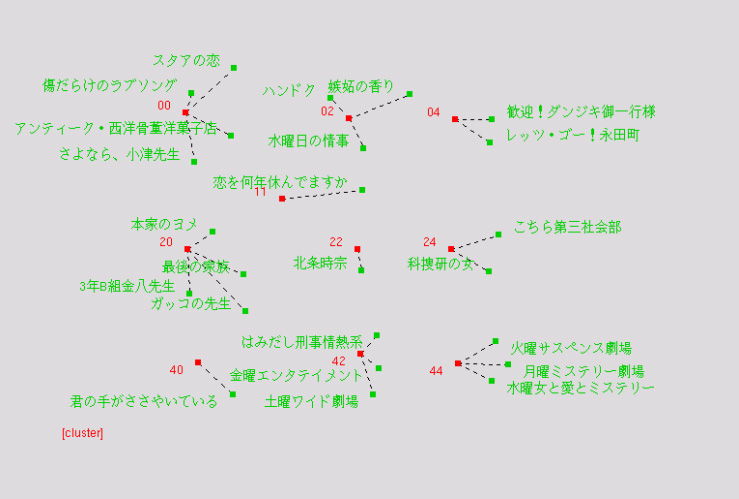
この結果は、各番組に寄せられた自由回答の中で、形容詞と動詞、固有名詞を除く名詞について、全体の語数の割合を取り、そのデータのみをKohonen分析にかけたものである。何となく似た番組が近いクラスタにいるような結果が出ていると言える。
また、eudaptics社のViscovery SOMineを利用して、同様のクラスタ化を行うと、以下のようになった。
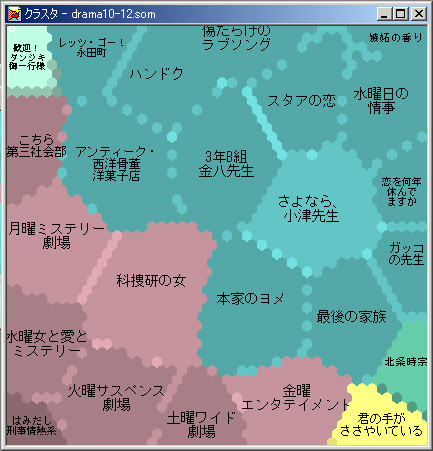
こちらも、似たような精度でクラスタ分けが出来ていると言えるであろう。これらはすべて形態素のみでクラスタリングされている。その他の要素をすべて排除して、ここまでの解析ができるということは、今後、さらに精度を高められる可能性を秘めていると言ってよいだろう。こういった解析を様々に見ていって、現在は手動でデータを作成し、解析ソフトにかけているのであるが、これを自動でできるようにアルゴリズムを解析し、データを自動で作成して、より自動解析の質を高めていきたい。
以上が「リサーチQ」の研究における今後の展望である。現在「リサーチQ」のようなWeb上での視聴質調査は他に類を見ない先駆け的な研究である。また、Web調査とその自動解析という点から見ても、大量データの自動解析というまったく新しい解析手法を確立するための非常に有意義な研究であり、今後とも、「リサーチQ」の研究に力を注いでいきたい。
「リサーチQ」URL:
http://www.rq-tv.com/
「IES Ver.2」URL:
http://ellington.gel.sfc.keio.ac.jp/rq/