2007年度 森基金成果報告書
IVVデータを用いたタンパク質の複合体の抽出
慶應義塾大学政策・メディア研究科後期博士課程2年
小澤陽介
1.研究背景
近年、タンパク質間相互作用のデータはY2H法、質量分析, In vitro virus法などの効率の良い実験手法によって大量に蓄積されてきている。しかしその大量の相互作用データから、実際に細胞内に存在する複合体を高精度で抽出することは難しい。タンパク質をノードに、相互作用をエッジにそれぞれ対応させたグラフ表現から、複合体を抽出する計算機科学の手法は、MCL、MCODE、など複数存在するが、それらは偽陽性のデータを多く含むことが知られている。その理由の一つはそれらのグラフが、一対一のタンパク質の相互作用データを集めたものに過ぎず、それぞれのエッジが同時に存在しうるかということに関しては考えられていないからである。タンパク質には他のタンパク質との結合の為に化学的な活性をもった部位(ドメイン)があり、多くの場合同じドメインでは一つのタンパク質としか結合できない。そこで理工学部柳川研究室と共同で、In Vitro Virus法で得られたタンパク質間相互作用のデータを用いて、タンパク質の結合ドメインを考慮した複合体の抽出を行う。
2.研究目的
(1)タンパク質間相互作用データから、複合体を抽出すること。また(2)結合の構造が明らかでない複合体に対して、IVV法で得られる結合ドメインの情報を適用・統合することにより、未知の結合構造を明らかにするとともに、物理的に不可能な結合を排除することで、複合体抽出の精度を向上させる。
3.研究方法
IVV法で得られたデータのほかにBIND、HPRDのような公共のタンパク質間相互作用データベースに蓄積された1対1のタンパク質間相互作用データを用いて、複合体の予測を行う。複合体の予測は大きく3つの手順にわかれる。
1).既知の複合体抽出のアルゴリズムを用いて、第一の複合体候補をあげ、2). IVV法で得られたデータやiPfamなどからドメイン間相互作用を抽出する3).2で得られたドメイン間相互作用を1で得られた第一の複合体予測結果にあてはめ、ドメイン間相互作用が同時になりたつものを、最終的に予測する複合体とする。ただし1つのドメインは1つのドメインとしか結合できないものと仮定する。
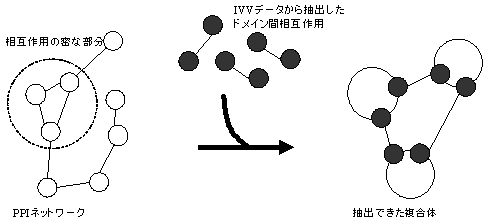
図1: ドメインを考慮した複合体の抽出
4.結果
ドメインを考慮して複合体を抽出した結果、4種類の既存の複合体抽出方法でドメインを考慮しない場合に比べて、敏感度が約2〜3倍に向上した。

表1: 既知の複合体の一部にマッチしたものの割合(既知の複合体にマッチした数/予測された複合体数)。括弧内は敏感度。
5.まとめ
・221個の新規複合体候補を抽出
・既知複合体抽出のセンシティビティを既存の手法に比べて、2〜3倍に向上
6.実績
ポスター発表(2件)
・小澤陽介, 斎藤輪太郎 、藤森茂雄、鹿島久嗣、柳川弘志、宮本悦子、冨田勝(2007) 結合ドメインを考慮したタンパク質複合体の予測手法, BMB2007, 横浜
・Yosuke Ozawa, Rintaro Saito, Shigeo Fujimori, Hisashi Kashima, Hiroshi Yanagawa, Etsuko Miyamoto-Sato, Masaru Tomita (2007) A novel method considering binding domain independency for extracting protein complexes, the 18th International Conference on Genome Informatics GIW 2007, Matrix, SINGAPORE
・