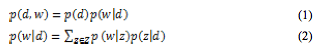
文書分類タスクでは,単語の出現頻度を元に作成されたベクトルに対し,次元圧縮を施してからクラスタリングを行う手法が一般的である。しかし,文書における単語の出現頻度には偏りがあることが多く,次元圧縮を行う際,標本である分類対象文書集合に対してオーバーフィットを起こしやすいという問題がある
一般的なクラスタリングにおいて,分類精度を向上させようとした場合,分類対象間にmust-linkのように制約を付与する半教師あり学習によって,分類精度を上げる手法があることは知られているが,文書分類の際に,これから分類しようとする文書間の関係を推定し,直接的に制約を付与することは難しい上に,これではオーバーフィットが起こりやすいという問題に対しての根本的な解決とはならない。ここで,文書間の関係に比べると比較的容易に手に入れることが可能である,単語間の関係を制約として用いるならば,標本に対するオーバーフィットを回避しつつ,分類精度を向上させることができるのではないかと考えた。
本研究では,確率的潜在意味解析 pLSI[1]に,分類対象文書に依存しない大域的な辞書を用い,外部から単語間 関係の制約を付与することによって,オーバーフィットを避けることが可能な文書分類手法を提案する。
pLSIは,Aspect model(隠れ変数モデル)に基づいて次元圧縮を行う手法である。Aspect modelにおいて,文書と単語の同時生起確率p(d,w)は,一般的に式(1)のように求められ,このときp(w|d)は式(2)のように表わされる。
式(2)を,ベイズの定理を用いて変形し,同時生起確率p(d,w)を求める式(1)に代入すると,式(3)のようになる。
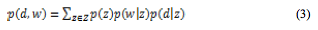
このとき,p(z),p(w|z)およびp(d|z)は,隠れ変数であるため直接求めることはできない。一般的には,式(4),(5)で表わされるEMアルゴリズムを用いて最尤推定を行う。
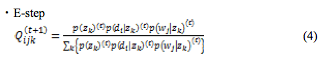
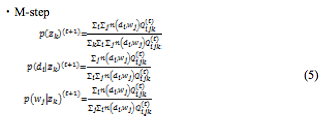
制約付きpLSIのモデルは,基本的に制約の無い場合と同様であるが,関連研究[4]にならい,確率分布p(z)の求め方を,次のように変更する。
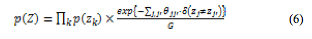
このときδ(・)はデルタ関数であり,隠れ変数との値が等しい場合は0,異なる場合は1をとる。また,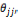 は制約項である。
は制約項である。
本研究において,提案モデルのパラメータ推定はEMアルゴリズムを用いて行う。前章でも述べたように,制約付きpLSIにおけるEMアルゴリズムによる更新手続きは,制約の無い場合の更新手続きと同じである。しかし,本研究で提案する制約付きpLSIでは,制約を付与することにより,各隠れ変数がそれぞれ独立であるというAspect modelでの仮定が成り立たなくなるため,E-stepでは以下の確率計算を行う必要が出てくる。
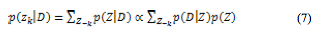
平均場近似[3]では,上記の確率分布p(D|Z)を式(8)のような形の分布Q(Z)で近似する。

上で示した近似分布Q(Z)のパラメータは,真の分布からのKLダイバージェンスが最小となるものを選ぶ。すなわち,近似分布を算出する作業は,任意のi,jに対し,以下の式(9)を最小化する問題となる。

この目的関数に対し,ラグランジュの未定乗数を導入して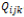 の極値条件を求めると,式(10)を得る。
の極値条件を求めると,式(10)を得る。
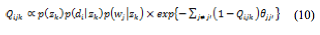
式(10)より,近似分布のパラメータを次の更新式に基づく反復法で求める。
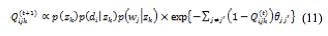
上の式について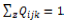 ,という条件を考えると,最終的に制約を組み込んだ場合のE-stepにおける更新式は,次のようになる。
,という条件を考えると,最終的に制約を組み込んだ場合のE-stepにおける更新式は,次のようになる。
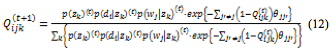
EMアルゴリズムには局所最適解に陥りやすいという問題があり,それは各パラメータの初期値に依存する。そのため本研究では,初期値の設定についても単語間の制約を反映させながら行う。具体的には,語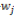 と語
と語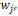 の間に制約を課す場合,確率
の間に制約を課す場合,確率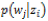 及び
及び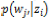 が,すべてのiについて等しくなるように初期値を設定した。
が,すべてのiについて等しくなるように初期値を設定した。
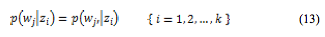
今回の実験では,クラスタリング対象文書データとして,毎日新聞データ集2004年度版より,国際・経済・家庭・文化・読書・科学・芸能・スポーツ・社会の9トピックについて,それぞれ1トピックあたり100記事ずつ,合計900文書を収集した。用意した文書集合から,文中に出現する名詞,動詞および形容詞と,その出現頻度を素性として取り出し,文書ベクトル とした。なお,形態素解析にはMeCabを用いた。
とした。なお,形態素解析にはMeCabを用いた。
次に,その文書ベクトルに対し,3章で説明した式(12),(5)を用いたEMアルゴリズムによって,以下の式(14)で計算される対数尤度が収束するまで,繰り返しパラメータラ推定を行った。本実験では,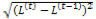 が0.001未満になった際,対数尤度が収束したものとして見なし,パラメータ推定を終了した。なお,本実験では,過学習を避けるため,Tempered EM[2]を適用した。
が0.001未満になった際,対数尤度が収束したものとして見なし,パラメータ推定を終了した。なお,本実験では,過学習を避けるため,Tempered EM[2]を適用した。
対数尤度が収束したのち,推定されたパラメータ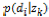 および
および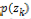 を利用し,式(15)により
を利用し,式(15)により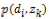 を計算し,得られた
を計算し,得られた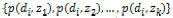 のうち,最大となるものをクラスタ番号として割り当てた。
のうち,最大となるものをクラスタ番号として割り当てた。
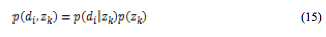
また,制約付きpLSIにおいて使用する単語間の制約については,Web文書から集めた100万文より,文中で共起する各単語ペアのχ2乗値を求め,それに定数を掛けたものを重みづけとして用いた。本実験では,提案モデルである制約付きpLSIの有効性を検証するため,制約を用いない場合のpLSIとの比較実験を行った。
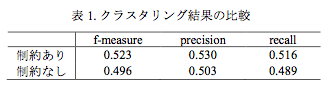
クラスタリング結果の精度・再現率からF値および精度,再現率を算出し,提案手法の評価を行った。なお,EMアルゴリズムは初期値依存性を持つため,制約付き,制約なし,ともに5回試行を行って,平均をとった。制約を用いた場合のF値は0.523,制約を用いない場合のF値は0.496となった。この結果から,単語間関係を制約として用いた提案手法のほうが,制約を用いなかった場合に比べてクラスタリング結果が良くなったことがわかる。
評価のところで詳しく説明しなかったが,制約を用いた場合は制約なしの場合に比べて,特に初期値依存が大きくなり,良い初期値から始まった場合はもちろん制約を用いなかった場合に比べて結果も良くなるが,悪い初期値から始まった場合は,制約を用いなかった場合に比べて結果が悪くなる場合もあり,結果の分散が大きくなった。これは,の初期値設定において,違う潜在トピックから派生しているにも関わらず,似た初期値が割り振られたためだと考えられる。これを解決するためには,今回行ったmust-linkのような同じ初期値を設定する手法の逆,つまり,cannot-linkのように,大きく違う初期値を割り振ることができたら,結果はさらに安定し, 精度が向上すると考えられる。
また,本研究における提案手法について,今回の実験ではWeb文書から抽出した単語間の関係を制約として用いたが,距離や重みといった単語間の関係の強さを数値として含む辞書であれば,他の辞書を利用することによっても同様の成果を期待することができる。例えば,連想概念辞書やEDR電子化辞書等,単語間の距離を含む辞書であれば,他の辞書を利用することによっても同様の成果を期待することができる。
ここで,辞書について,いくつか選択肢がある中で,連想概念辞書を利用することの意義のひとつとしては,「人間の直観的な単語間の関係に即した文書分類が可能になる」ということが挙げられるだろう。このことは,逆にいえば,個人個人で異なる辞書を用意することによって「その人の直観的な単語間の関係に即した文書分類が可能になる」ということである。本研究のモチベーションとなっている,検索エンジンに応用することを考えるなら,検索結果のトピック分類において,その人の視点・思考を反映し,パーソナライズ化を実現させる可能性をも秘めているといえるだろう。