Embracing Huge Numbers of Volatile Clients: Web Sites as Distributed Video Analysis Engines via Service Overlay
Mori Memorial Research Fund Report (2010 Academic Year)
By Jeremy Hall – 1st Year Doctor's Program
Kiyoki Laboratory
February 27th 2011
Overview
This semester I focused on how to organize a website and its users into a platform for performing massively parallel and distributed video analysis. I submitted my research to the IEEE ICWS 2011 (International Conference on Web Services) conference:
http://conferences.computer.org/icws/2011/
Titled: "Embracing Huge Numbers of Volatile Clients: Web Sites as Distributed Video Analysis Engines via Service Overlay"
This paper is still pending acceptance.
Research Abstract
The following is the abstract I used for the IEEE ICWS 2011 conference paper, and nicely summarizes the research I engaged in:
"This paper describes a platform that uses a service-overlay to enhance the abilities of an existing website’s infrastructure to handle massive distributed analysis. This platform utilizes the collective power of a website’s users as the primary platform upon which this analysis occurs without interfering with those users’ experience of the website they are browsing. The platform employs a novel task-allocation strategy specifically tailored to the realities of web infrastructure, able to handle large numbers of extremely volatile and unreliable clients by distributing the role of task-allocation itself, and completely forgoing the management of clients. The role of the platform is to separate the distributed analysis which runs on top of the platform from the chosen task-allocation strategy. Due to constraints on the type of distributed analysis that can be performed by this platform, this paper focuses on video analysis which is especially well suited to the strengths of the platform, and discusses a prototype implementation of an advanced content-based video analysis algorithm. Finally, the behavior of the platform is verified based on experiments performed with a prototype implementation and a separate task-allocation simulator.”
Overview and Goal of our Platform
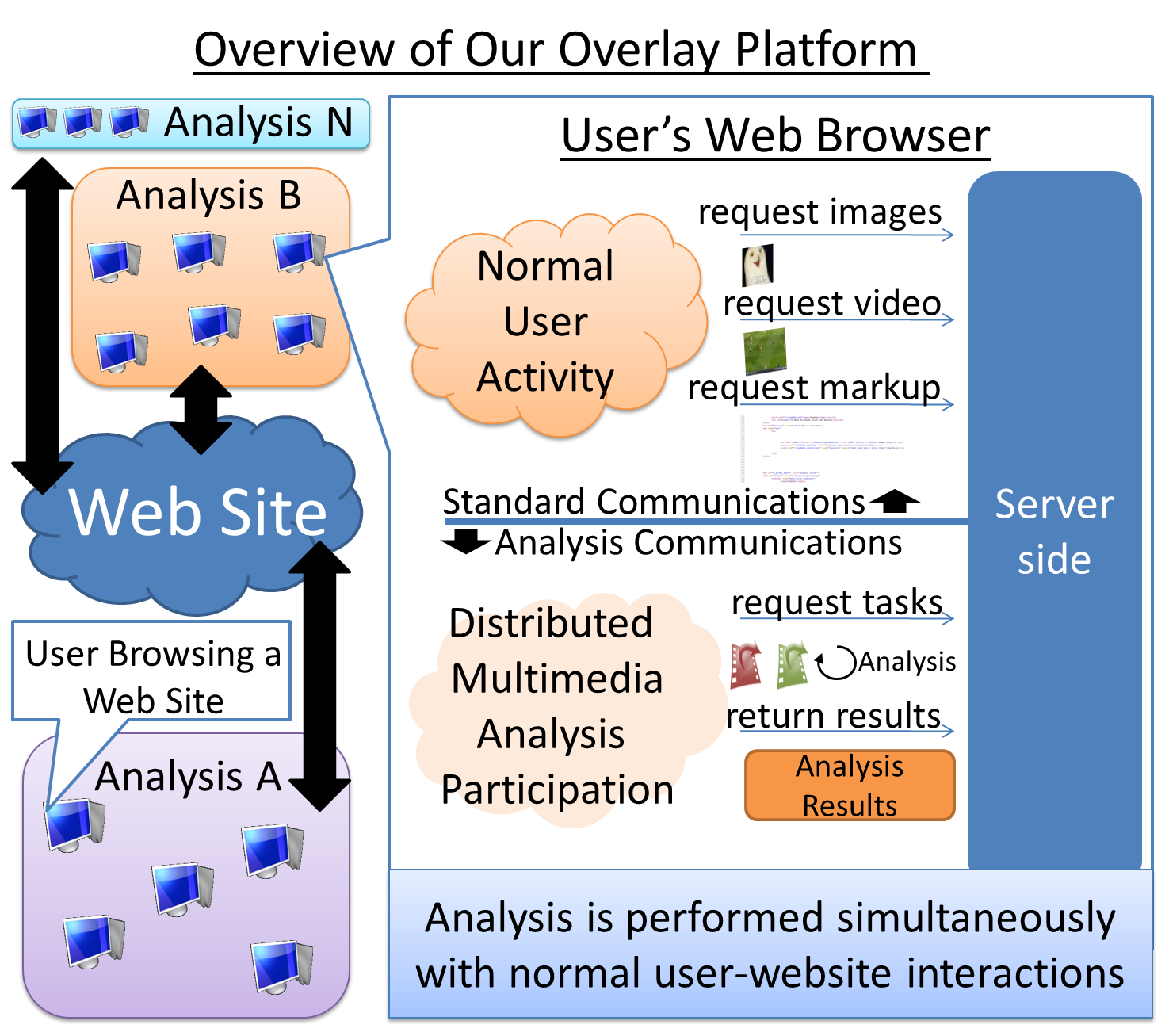 This research focuses on overlaying a platform for performing video analysis on top of a website. Web infrastructure poses unique challenges as compared to other environments where current distributed computing technology runs. Our platform must deal with extremely volatile clients, which place the video analysis they are participating in as extremely low priority, and thus our platform must be able to handle thousands of clients connecting and disconnecting at will, with no warning or communications as to the clients' intentions. Other distributed systems focus on closely monitoring and controlling the clients participating in a distributed analysis. Our platform takes a completely different approach however, in order to take full advantage of web infrastructure's parallelism and scalability, so that it can run on existing resources.
This research focuses on overlaying a platform for performing video analysis on top of a website. Web infrastructure poses unique challenges as compared to other environments where current distributed computing technology runs. Our platform must deal with extremely volatile clients, which place the video analysis they are participating in as extremely low priority, and thus our platform must be able to handle thousands of clients connecting and disconnecting at will, with no warning or communications as to the clients' intentions. Other distributed systems focus on closely monitoring and controlling the clients participating in a distributed analysis. Our platform takes a completely different approach however, in order to take full advantage of web infrastructure's parallelism and scalability, so that it can run on existing resources.Novelty of our Platform: Our Two-Pronged Task-Allocation Strategy
The platform is formed by two layers. The lower "Task Allocation Layer" completely abstracts and separates the actual video analysis from having to worry about clients or task distribution. The upper-layer called the "Analysis Application Layer" merely worries about generating and processing Tasks. When to process these tasks, and how to distribute them is completely handled by the Task Allocation Layer.
Our Task-Allocation strategy is to take advantage of large numbers of distributed and volatile clients. In this case, volatile refers to the unpredictability of how long a client will remain part of an analysis. A volatile client is unreliable, and may connect or disconnect at any time. Taking advantage of those clients is made possible by trading per-client control and algorithmic efficiency for scalability and parallelism. Our system focuses on results rather than clients. The actual assignment of tasks is distributed via our Distributed Client-Autonomous Task Selection Strategy, which relies on random selection. Rather than having a central view of which work is assigned to which client, our strategy is to allow the clients to choose the work. This means that there is no management overhead to having large numbers of clients, and that the volatility of clients has no impact on the efficiency of our task-allocation strategy (although it will certainly impact the speed at which an analysis takes place). A random-selection strategy such as ours is algorithmically inefficient however. This is why we designed the second component in our Task-Allocation Layer, our Remapping Algorithm. The remapping algorithm attempts to prevent collisions in client’s random selections, thus increasing overall algorithmic efficiencies. The Remapping Algorithm achieves this without knowing client-state, and thus allows us to keep the advantages of our Distributed Client-Autonomous Task Selection Strategy with very little tradeoff.
By combining both our Distributed Client-Autonomous Task Selection Strategy and our Remapping Algorithm, we get an extremely parallel and scalable system which can handle massive numbers of volatile clients, and a high degree of algorithmic efficiency.
Future Research & Paper Submissions
- Multiple simultaneous analysis algorithms running on the Platform.
- Multiple-server scenarios
- Experiments with large numbers of clients proving the real-world potential for the Platform's scalability
- Experiments with upcoming mobile devices such as cell phone's and tablets to show the future viability of the Platform