<<Taikichiro
Mori Memorial Research Fund>>
Graduate Student Researcher Development Grant
Report
Noise reduction mechanisms for speech
enhancement
Nguyen Anh Duc, e-mail:
ducna80@sfc.keio.ac.jp
I.
Introduction
Speech enhancement is concerned with
improving the quality and intelligibility of speech contaminated by noise, and
it is sometimes referred as noise reduction techniques. It has a variety of
applications in telecommunications, automatic speech recognition or in digital
aid.
|
|
|
Figure 1.
An example of communication in a noisy
environment. |
There have been
numerous proposed algorithms for speech enhancement and related applications. We
can classify them based on the number of microphones (single or
multiple-microphones), the domain of processing, e.g., time domain or frequency
domain, and techniques to process the information, e.g., spectral subtraction,
Wiener filters, subspace method or statistical-model-based
mechanisms.
This research considers
single-channel speech enhancement mechanisms using statistics and estimation
techniques to process data in the frequency domain. By using one microphone
(single-channel), the scope of this research is limited in monaural hearing
only. The noise here is assumed statistically independent with the considered
speech signal.
The main contributions
of this research are two new effective speech spectral amplitude estimators for
speech enhancement. The originality of these estimators is a novel
perceptually-motivated cost function, which is developed based on
characteristics of the human auditory system. The experimental
results present advantages of the proposals over well-known methods in terms of
both better noise reduction and less speech
distortion.
II. Statistical-model-based mechanisms for
single-channel speech enhancement
II.1 Statistical-model-based mechanisms for
single-channel speech enhancement
In this approach,
the speech enhancement problem is put in statistics and estimation frameworks.
Given a set of observations, here are the Discrete Fourier Transform (DFT) coefficients of the noisy speech, i.e., the noisy
signal spectrum; we wish to estimate the values of the unknown DFT coefficients of the clean speech, i.e., the clean signal
spectrum. In order to find the estimation of the clean speech, some prior
knowledge, i.e., statistical properties, of noise and clean speech themselves
should be known in advance. These properties are often the shape of the
distribution, e.g., Gaussian, non-Gaussian, and the independence(uncorrelated)-or-not issues among speech and
nose components. Then, from this knowledge, related statistics, e.g., expected
value and variance, are calculated. Finally, estimation
techniques, including both conventional estimators where the parameters of
interest are treated as unknown but deterministic variables, e.g., Maximum
Likelihood Estimator (MLE), and Bayesian ones where
the parameters of interest are treated as random variables with some prior
distribution properties, e.g., Maximum A Posteriori
(MAP), Minimum Mean Square Error (MMSE), come into
play. All researches that have been done in this direction relate to the three
above steps. The main contribution of this research lies on the last step,
proposing novel and more efficient estimators.
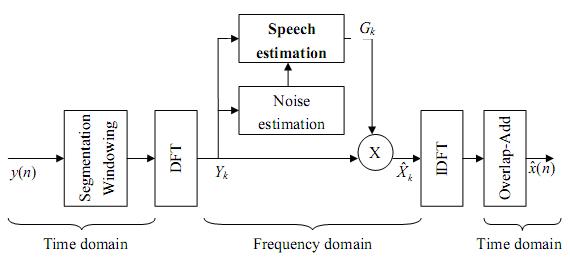
The general diagram for
a typical single-channel statistical-model-based speech enhancement algorithm is
presented in Figure 2.
|
|
|
Figure
2. General diagram of a single-channel
statistical-model-based speech enhancement algorithm in the frequency domain
. |
II.2 Contributions of this
research
The core
contribution of this research is a new cost function for Bayesian estimation.
That cost function is the weighted squared error between the real and the
estimated values. While the squared error of speech log-spectral amplitude is
motivated by the more perceptual relevance of loudness than intensity itself,
the weighting factor comes from the observation of the auditory masking effects.
Therefore, this cost function takes advantages of the both useful properties of
the human hearing system, the masking effects and perceived
loudness.
Based on this cost function, two speech
(log) spectral amplitude estimators are constructed under the Rayleigh and Chi speech prior assumptions respectively.
While the Rayleigh prior is theoretically derived, the
Chi prior is more generalized and capable of reflecting the super-Gaussian
distributed nature of speech spectral amplitude. Discussions on how to make
these proposed algorithms practical for real applications are also presented.
When evaluating these proposed estimators with speech signals contaminated by
various noise sources at different input signal-to-noise ratios, the
experimental results show that they achieve better performance than the
well-known Minimum Mean Square Error log-spectral amplitude estimator in terms
of both noise reduction and speech quality.
III. Feature work
Some problems still remain for the future
work as follows:
1.
Improve the way of implementing proposed estimators, more
computationally efficient. Since it is rather complicated to compute these
estimators, we have to use the lookup table technique (LUT) to mitigate the problem and make the proposals implementabe for real applications. The disadvantage of the
LUT is that it consumes some significant amount of
memory to store all the pre-computed data. The higher precision (better
accuracy) we need, the more memory is required.
2.
Conduct the implementation and evaluation of the second estimator,
which is constructed based on the Chi speech prior, and find out the best values
of the parameters.
3.
Consider the frequency dependence of the human perception or a
multi-band speech enhancement strategy.
4.
Incorporate speech presence uncertainty with the proposed estimators.
This method substantially reduces the residual noise, and therefore, improves
the performance of the proposals.
References
|
[1] |
A. D. Nguyen, K. Naoe,
and Y. Takefuji, “A new log-spectral amplitude
estimator using the weighted Euclidean distortion measure for speech
enhancement,” Proc. 26th IEEE Convention of Electrical and
Electronics Engineers in Israel (IEEEI), pp.
000675-000679, 2010. |
|
[2] |
A. D. Nguyen, “Statistical model based mechanisms
for single-channel speech enhancement,” Master Thesis, Keio SFC, 2011. |
|
|
|