「プログラムの改変が不要な使用プロセッサ動的切替手法」
研究成果報告書
政策・メディア研究科 修士課程1年 堀川 哲郎
研究課題
近年,PCでは動画の変換等にGPU(Graphics Processing Unit)を汎用的に用いて高速化を図るアプリケーションが増加している. そのようなアプリケーションと動画再生やゲーム等のアプリケーションが同時にGPUを利用した場合,描画性能の低下等ユーザーエクスペリエンスの低下に繋がる. ハイパフォーマンスコンピューティング分野を対象とする既存研究では考慮されなかったこのような問題に対し, 本研究の提案するシステムでは他者が作成した既存のアプリケーションの使用プロセッサの切り替えを実現し,描画性能の低下等を防止出来る. また,プロセッサ切り替えにアプリケーションのバイナリ変更を不要とすることで,多数のアプリケーションへの対応が可能となり, 著作権等の法的問題も同時にクリアすることが出来る.
研究の背景と問題意識
近年,PC等で用いられるグラフィック処理用のプロセッサ,GPU(Graphics Processing Unit)を汎用処理に用いる GPGPU(General-Purpose computing on Graphics Processing Units)が盛んに行われている. GPUはCPU(Central Processing Unit)と比較して並列性の高い処理を極めて高速に実行出来るため, 動画のトランスコードや物理シミュレーション等のアプリケーションにおいてGPGPUの利用は非常に効果的である.
GPGPUの活用が進む中で,PCでは将来的にPC特有の問題が生じると考えられる. PCにおいてはユーザーエクスペリエンスの低下を防ぐことが極めて重要であり,場合によっては単位時間あたりの処理能力の向上等よりも優先される. 例えば,GPGPUを利用するアプリケーションを実行した場合,他のアプリケーションの描画性能及び応答性が低下し, 特に3Dゲームではフレームレートの大幅な落ち込み等の問題を引き起こす.
今後,GPGPUを利用するアプリケーションの増加傾向は続くと見込まれるため,前述のようなGPUリソース利用の競合が顕著になると考えられる. したがって,GPUのリソース利用の競合時にOS・またはランタイム等の実行環境が一部のアプリケーションに対して, CPUを利用するよう強制,あるいは指示出来るようにするシステムの構築が,第1の課題となる.
既存研究として,使用プロセッサの動的な切り替えとCPU・GPU間のタスクスケジューリングを実現する手法は多数提案されているが, それらの研究はHPC(High Performance Computing)分野を対象としており,一般的なユーザーが使用するPCは対象とされていない. そのため,前述のような描画性能低下に伴うユーザーエクスペリエンスの低下等は考慮されておらず,PCにそれらの既存の手法を適用することは現実的でない.
また,既存の手法では動的な使用プロセッサの切り替えを実現するにあたり,アプリケーションを専用に設計する, もしくはアプリケーションを改変して対応させることが必要である.しかし,PCにインストールされるアプリケーションは, 知的財産の保護という法的な側面,及びソフトウェアのライセンスという側面から,改変は多くの場合不可能である. 仮に協力的な一部のベンダーがアプリケーションを再設計し,使用プロセッサの動的な切り替えに対応させたとしても, ごく一部のアプリケーションでのみ切り替えられるだけでは,GPU利用のリソース競合を防ぐことは不可能である. したがって,アプリケーションのソースコードからバイナリまで,一切の変更を必要とせずに動的な使用プロセッサの切り替えを実現することが,第2の課題となる.
ここまで,GPUのリソース利用が競合した場合にCPUを利用させるという例を挙げて説明を行ってきたが,実際の問題はそれほど単純ではない. HPC分野においては,使用プロセッサ選択の指針がパフォーマンスの最大化や消費電力の最小化等に限られているのに対して,PCではその指針はユー ザーの希望に大きく依存する. 例えば,アプリケーションの描画性能低下に対する不満の度合いはユーザーによって異なるうえ, GPUを利用しようとするアプリケーションの実行速度と他のアプリケーションの描画性能との間のトレードオフの間でどちらを優先するかは, 同一ユーザーであっても時と場合によって異なる. 例えば,3Dゲームに没入したい場合には他のアプリケーションによるGPUの利用を控えてゲームアプリケーションの描画能力を維持するべきであるが, ゲームはただの暇つぶしであり,バックグラウンドで行っている動画のトランスコード速度の方が重要な場合には,動画のトランスコードにGPUを利用さ せるべきである. したがって,このように常に変化するユーザーの希望を反映出来る仕組みを構築し,ユーザーの希望を自動的に推測することで, ユーザー自身による希望の入力という負担を軽減することが,第3の課題となる.
提案するシステムとアプローチ
前述の第1の課題及び第3の課題を解決するため,本研究の提案するシステムでは以下のようなステップを繰り返し,使用プロセッサの決定と切り替えを行う.
- 実行中のアプリケーション一覧等,PCの使用状況に関する情報を収集する
- 保存されているユーザーの希望プロファイル一覧から,現在のPCの使用状況に最も近いものを推測する
- 使用プロセッサの切り替えが可能なアプリケーションが使用すべきプロセッサを問い合わせる
- 使用状況及びユーザー希望のプロファイルを元に使用すべきプロセッサをアプリケーションに対して返答する
- 使用プロセッサの切り替えが可能なアプリケーションが,実際にプロセッサの使用を開始する
ユーザーの希望を保存するプロファイルには,PCの使用状況の条件や,どのアプリケーションにGPUの利用を優先し, どのアプリケーションのGPU利用を禁止するか,といった情報を記述する必要がある. 本研究では,プロファイルをユーザーが容易に作成出来るようにするためのGUIの実装も行う. また,プロファイルの指針を元に,実際のプロセッサ割り当てを決定するアルゴリズムについても実装を行う. これは特にユーザーが画面の描画速度低下等を気に留めない場合に,パフォーマンス等の最適化を行う際重要となる. アルゴリズムについては,既存の研究によるものや自ら開発したものを交えて現在検討を行っている.
前述の第2の課題であるバイナリ互換性の確保に関しては,図1のような機構を実装して解決する. APIフックを用いることで,使用するプロセッサの指定をオーバーライドすることが基本的な手法であるが, 実際にはその指定のみを変更するとアプリケーションが正常に動作しない事例が多数発生する. アプリケーションが,本来使用を試みていたプロセッサと異なるプロセッサを利用させられていることに気付いた場合, アプリケーションがエラーとして処理を停止してしまったり,あるいはアプリケーションが正常に動作出来なくなったりしてしまう. そのため,本研究ではアプリケーションに対するプロセッサ情報の提示内容を変更したり, アプリケーションに対してアプリケーションが指定した本来のプロセッサを使用しているように偽装を行ったりすることにより,アプリケーションの互換性を確保する.
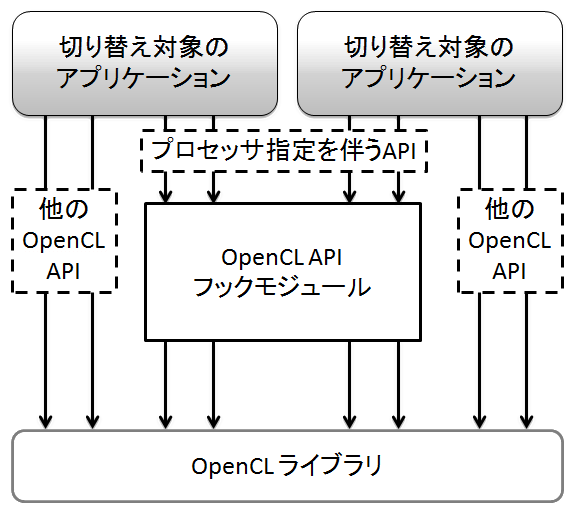
本研究では,動的な使用プロセッサ切り替えを実現するアプリケーションの対象をCPU・GPU双方のプロセッサが利用可能なオープンスタンダードな フレームワークであるOpenCL(Open Compute Language)を用いて実装されたアプリケーションと想定している. そのため,OpenCLが持つ使用プロセッサの指定を行う全てのAPIをフックし,使用プロセッサ指定の問い合わせと指定の書き換えを行う. しかし,使用プロセッサの指定を引数に持つ全てのAPIが呼び出される度に問い合わせを行うことは,非常に非効率的でパフォーマンスに悪影響を及ぼす. そのため,問い合わせ回数を削減するための手法を実装する. 現状では,プロセッサ情報取得APIが呼ばれた際の使用プロセッサ問い合わせを必要最小限となるようにして,パフォーマンス向上を図っている.
アプリケーションに対するプロセッサ情報の提示内容の変更や使用プロセッサ情報の偽装に関しては,
原則として卒業論文における研究で得られた表1におけるBCDAの順に適用を試みるポリシーを適用する.
このポリシーを用いることで,アプリケーションのソースコードが公開されていないアプリケーションを含め,バイナリを変更せずに使用プロセッサの動的な変更が実現出来てい
る. しかし,動作に異常を来して使用プロセッサの切り替えを行うことが出来ないアプリケーションもあるため,
実際に世界で公開されているアプリケーションに対して様々なハードウェア構成で互換性を検証中である.
今後,必要に応じてプロセッサ情報の偽装方法を変更し,さらなる互換性向上を図りたい.

研究成果
論文執筆・学会発表
卒業論文の内容を中心に評価などを追加し,並列コンピューティングに関する国際学会であるEuro-Par 2011のワークショップ
UnConventional High Performance Computing 2011 (UCHPC,
http://www.lrr.in.tum.de/~weidendo/uchpc11/) へ論文を投稿した.
フォーマットは,1カラム10ページである.論文がアクセプトされたため,フランスのボルドーⅡ大学にて口頭発表を行った.
| 国際会議名 |
Euro-Par 2011 |
| ワークショップ名 |
UnConventional High Performance Computing 2011 |
| 開催場所 |
Bordeaux II University (Bordeaux, France) |
| 開催日時 |
2011/08/29 - 2011/09/02 |
| 発表日時 |
2011/08/29, 15:20 - 15:40 |

論文及び発表に対するコメントは以下の4点である.
- 使用プロセッサを切り替え可能なタイミングが限られている
- GPUに最適化されたOpenCLコードをCPUで実行してしまうリスクがある
- Windows以外においても実装可能か
- プロセッサ切り替えに伴うオーバーヘッドの評価が不足している
以上のうち,1~3に関してはcamera ready提出時に修正済みである.
1に関しては,現状の実装よりも細かい粒度で使用プロセッサを切り替えるためには,OpenCLの規格上仮想ドライバ以外の方法では実現出来ないため, アプリケーションやハードウェアに対する互換性が低下したり,アプリケーションが持つ各プロセッサへの最適化機能の利用が難しくなるなどの問題があ る. 既存研究では,OpenCLの仮想デバイスを作成するものもあるが,対象はHigh Performance Computing(HPC)である. PCでは,利用されるハードウェアやソフトウェアの組み合わせが無数にあるため,互換性等の面から現実的でない.
2に関しては,アプリケーションに対して出来る限り実際のプロセッサ情報を見せるようにしているため, 問題が発生しうる機会はアプリケーションに対してOpenCLデバイスの情報を完全に偽装して提供している場合のみである. OpenCLのデバイス情報を偽装している場合の対処としては,既存研究のようにオンラインでOpenCL Cコードを最適化するという方法と各デバイス向けの OpenCL Cコードをキャッシュしておき,必要に応じて利用するという方法とが考えられるが,今後修士論文に向けてパフォーマンス計測を行いながら具体的な解決策を模索していきた い.
3に関しては,APIフック機能を提供するOSであれば,OSの種類を問わずに実装出来るが,他のOSが提供するAPIフック機能はWindowsと比べると柔軟性が低い. したがって,同様の手法を他のOSに適用することは可能であるが,Windowsで利用する場合と比べるとアプリケーションの安定性等が犠牲になる可能性が高い.
4に関しては,論文執筆時点で切り替えが可能なアプリケーションやハードウェア構成が非常に限定的であり, 実装方法の大幅な変更を必要としている可能性が高いため,評価を見送った. 今後ハードウェアやアプリケーションへの互換性をある程度確保出来た時点で,本システムで提案する手法・実装のオーバーヘッドを評価したい.
なお,論文は今後パブリッシュされる予定である.
SFC Openc Research Forum
上記UCHPCへの論文投稿後,より多くのハードウェア構成で動作出来るよう実装に改良を加え,SFC ORFで発表を行った.
会場では,ポスター展示と資料配付のほか,AMDのCPU及びGPUを搭載するラップトップPCを設置し,
他者が作成し一般に配布されているアプリケーションに対して,使用プロセッサの切り替えを行うデモを行った.
発表を通じて,研究のメリットが顕著となるシナリオが不足しているといった研究の問題点が明らかになったため,
修士論文に向けてパフォーマンスの検証を徹底し,シナリオの数を揃えていく予定である.
| 開催場所 |
東京ミッドタウンホール B1F |
| 開催日時 |
2011/11/22 - 2011/11/23 |
| 発表日時 |
2011/11/22 - 2011/11/23 10:00 -
19:30 |

システムの実装・改良
2011年度を通じて,システムに以下の改良を行った.
- ハードウェア互換性の向上
- アプリケーション互換性の向上
1に関しては,卒業論文において動作出来ていたIntel CPU + AMD GPU x1のハードウェア構成に加えて,AMD CPU + AMD GPU x2においても動作出来るようシステムの改良を行った.2つより多くのAMD GPUにおける動作も可能と考えられるため,今後検証を行う予定である. また,nVidia GPU利用時の動作に関して調査した. 現状ではAMDのOpenCL フレームワークとnVidiaのフレームワークが共にインストールされている環境では切り替えが出来ないため, システムが正しく動作出来るよう現状改良を続けている.
2に関しては,卒業論文の時点では検証が行っていなかったLuxMarkで動作を検証したところ正しく動作しなかったため,システムを改良し,アプリケーションに対応させ た. 加えて,OpenCL N-Bodyでの動作検証も行い,システムが正しく動作することを確認した.
システムの評価等
様々なハードウェア・OpenCLフレームワークの組み合わせにおいて,システムの動作確認及び評価を行った. 卒業論文ではIntel Core i7 920 CPU + AMD RADEON HD 4850を搭載しAMDのOpenCLフレームワークを利用する環境で実装・評価を行ったが, 本年度は,以下の環境で実装・動作確認等を行った.
- Intel Core i7 920 + AMD RADEON HD 5770 / AMD OpenCL Framework
- Intel Core i7 620M + nVidia GeForce GT330M / AMD & nVidia & Intel OpenCL Frameworks
- AMD Fusion APU A6-3400M + AMD RADEON HD 6650M / AMD OpenCL Framework
- AMD PhenomII 1100T BE + AMD RADEON HD 6970 x2 / AMD OpenCL Framework
- Intel Core i7 2760QM + nVidia Geforce GT555M / AMD & nVidia & Intel OpenCL Frameworks
- AMD PhenomII 940 BE + AMD RADEON 6970 + nVidia GeForce GTX460 / AMD OpenCL Framework
ラップトップPCにおいては最新のGPUドライバが使えない場合や特殊なドライバが利用されているといったことが原因でシステムを正しく評価出来ないものもあったが, おおむねAMDのOpenCL Frameworkを利用し,AMDのGPUを利用する場合は動作出来る段階に達した.
nVidiaのOpenCL Framworkを利用した場合,複数のプラットフォームにまたがるOpenCL Contextを作ることが出来ないというOpenCLの仕様上の制限があるため, 卒業論文で提案している方法では切り替えが出来ない.そのため,新たに複数プラットフォームに対応するための実装を行っている.
また,Intel OpenCL Frameworkを利用した場合,Microsoft C Runtimeの読み込みが出来なくなりアプリケーションが起動しなくなるなどの問題が発生する. これはIntel TBB(Threading Building Blocks)を利用したアプリケーションに本システムを適用した場合にも発生するため, Intelの利用しているライブラリやコンパイラに原因があると考えられる. 今後原因を究明し,これらの環境でも動作出来るようシステムの改良を進めたい.
Copyright © 2011-2012 Tetsuro Horikawa. All Rights Reserved.