2012年度 森泰吉郎記念研究振興基金 研究助成金 報告書
透過的分散コンピューティングの為の共有メモリ機構
慶應義塾大学大学院 政策・メディア研究科 後期博士課程3年
松谷健史
はじめに
コンピュータの処理能力に影響するCPU、メモリ、拡張機器などのハードウェア構成は,物理的な接続によって静的に決定されている。
コンピュータ内部のハードウェアはバスによって接続されているが、バスには距離、デバイスの数、並列トランザクション数、再構成可能性の点で制限がある。
特別に設計されたI/Oネットワークでさえ、それら制限の一部分を解決するにすぎない。
この問題を解決するために、本論文ではIPレベルネットワークをCPUとメモリ、I/Oデバイスのバス相互接続に用いる手法を提案する。
提案内容の一部を実現するために、バスのプロトコルとインターネットプロトコルとを相互に変換するIPバスブリッジを設計し、FPGAボード上に実装、評価した。
IPバスブリッジはRISCアーキテクチャ CPUとメモリと拡張機器をEthernetによって接続しており、IPを使用した接続と使用しない接続の両方に対応している。
2011年度はおもに下記の設計と実装をおこなった
•
汎用PCへの対応
PCIボードへの移植
PCIバス対応
本ボードから PC内蔵メインメモリへのダイレクトにアクセスするためのDMA機構の追加
本研究はIPネットワークを用いるため、ネットワーク転送機器の遅延を少なくすることが求められ
2012年度は本アーキテクチャを実現するために不可欠となる、低遅延IP転送が可能なネットワーク転送機器を設計・実装した
今年度 研究成果
・成果物:本アーキテクチャを実現するためのネットワーク転送機構を実装したFPGAによる低遅延IP転送ネットワークスイッチ
本研究の目的
本研究の目的はインターネット上においてアプリケーションやユーザの要求に応じてハードウェアを動的に割り当てるコンピュータアーキテクチャを実現するために、バスの距離と数の制限に関する問題を解決することである。
そのためにハードウェアの拡張をおこなう際に重要となる、バスの距離と数の制限を解決する必要がある。
1.距離の制限
距離の制限とは、CPUやメモリ、周辺装置を増設するバスは主に匡体の中にあるため、接続できる距離に限界があることを示す。
2.数の制限
数の制限とは、物理的なバスの接続数や仕様によってハードウェア増設できる数が制限されてしまうことを示す。
3.アクセス遅延の制限
アクセス遅延の制限とは、メモリやI/Oに対して遅いバスなどを用いることによりアクセスに一定時間以上の遅延がかかりタイムアウトや性能の著しい低下などを招き利用を制限されることを示す。
本研究ではネットワーク技術を使い、IPとハードウェアのバスレベルのプロトコル変換ができる専用のバスブリッジを設計することにより、バスの距離と数の制限に関する問題、メモリのレプリケーション機構によってアクセス遅延の制限を解決する。
バスの制約をなくし各コンピュータのバスをIPで接続することにより、同一のOSとソフトウェアを異なる物理マシン間で分散コンピューティングすることができる。
このような分散コンピューティングをバスレイヤー分散コンピューティングとして図1に示す。
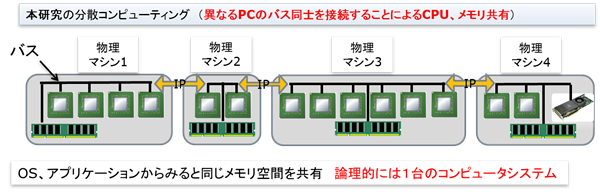
図1: バスレイヤー 分散コンピューティング
解決へのアプローチ
上記の問題を解決するために、次のようなアプローチをとる。
1. グローバル接続
コンピュータバスには距離や接続数の制限がある。本機構ではバス信号を既存の通信ネットワークプロトコルに変換する機能をもつことによりグローバル接続を実現する。
2. 透過的アクセス
接続先の回路がローカル上にある場合でも、ネットワークを超えたリモート上にある場合でも意識することなく透過的に利用できる必要がある。また、回路が直接通信ネットワークプロトコルで接続することは回路規模の増加や互換性の低下につながるため、回路間にブリッジ機構を設けることにより実現する。
3. 低遅延
リモート回路への接続ではネットワークプロトコルへ変換されるため遅延の増加がみこまれる。本機構では低遅延化を実現するために、ネットワークプロトコルへの変換にソフトウェア処理は一切おこなわず、電子回路のデータフロー処理によってネットワーク処理を実現できる専用のLANコントローラを設計する。
4. リモート接続におけるメモリ遅延対策
メモリ回路がリモートにある場合において、ワード単位でネットワークを経由して頻繁にアクセスを行うと遅延の影響は大きく、使用用途によっては現実的ではない。
本機構では、ブリッジ内にメモリーレプリケーション機構を設計することでリモートメモリとのアクセス回数を大幅に削減し遅延の問題を軽減化させる。
5. 柔軟性のある回路接続
通常、バスに接続される回路は同一バス内のCPUやメモリとしか接続が行われることがなく、ハードウェアの構成変更がない限り接続先は固定となる。本設計ではネットワークを経由して様々な回路と動的に接続するための機構が必要になる。
IPバスコンピュータの設計
実装の対象は本機構を持つブリッジ回路とCPU、Video回路、Ethernet回路、PS2インターフェイス回路、UART回路とする。
全体図の概要を図 2に示す。
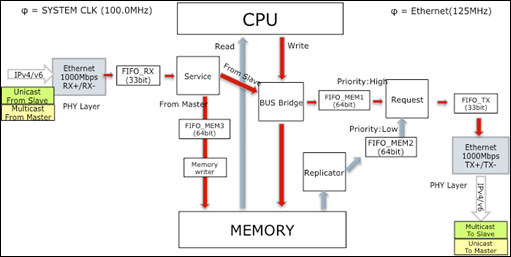
図2: 設計概要
PC用 PCIバスボード実装
本研究で設計したIPバスココンピュータの有用性を調べていくために市販のFPGAボード上に回路を構築した。
FPGAボードおよび開発環境を下記に示す。
FPGAボード仕様
|
ボード名称 |
Stanford University NetFPGAボード |
|
FPGA |
Xilinx Virtex 2Pro, Spartan-2 (PCI制御) |
|
コンピュータバス |
PCI 2.1 (32Bit/33MHz) |
|
LAN回路 |
Quard Gigabit Ethernet (1000BASE-T) |
|
SMP回路 |
IPI, Local Timer |
|
ブリッジ回路 |
IP/BUS Wired 変換 |
開発環境
|
使用言語 |
Verilog HDL言語 |
|
論理合成ツール |
Xilinx ISE 13.4 |
|
回路シミュレータ |
Xilinx Simulator および Veritak Win |
|
|
|
2012年度の研究概要
昨年度設計・開発した汎用PC用FPGAボードを接続するためのネットワーク転送スイッチの設計・実装を行う。
通常スイッチやルータなどのネットワーク機器が行う処理をFPGA(Field Programmable Gateway Array) でオフローディングさせる事により転送遅延を大幅に削減した。
アプローチ
ネットワーク転送装置の概要を図3に示す。
GigaPort#0より受信されたパケットデータはPHY層(PCS/PMA/PMD)によってディジタル8ビットデータに変換され、ASICやFPGA上のユーザ論理回路に送信される。
ユーザー論理回路ではパケットの送信先のLookupやパケットヘッダーなどの書き換えを行い、共有バスやクロスバーなどを経由し送信ポートに該当するPHYへ転送され該当する受信ポートへ送信される。
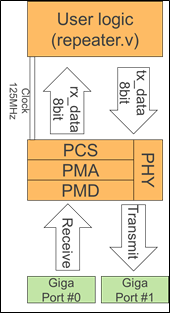
図3:ネットワーク転送フロー
図4にはユーザー論理回路の処理時間を0と仮定した場合において転送に必要になるプロセスを示したものである。上は受信の様子を示し、DestIPを受信してから転送先ポートやゲートウェイを調べるためにIP Lookupを開始する、IP Lookupが完了した時点ではじめて転送先への送信処理が行われる(画面下部分)。
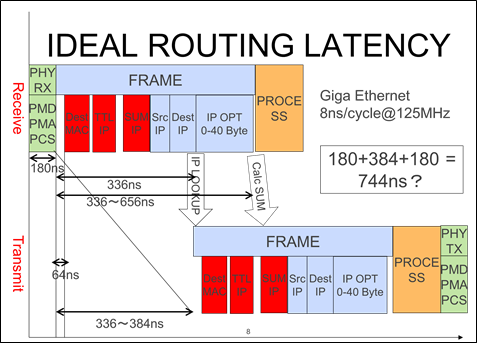
図4: 理想的な転送遅延
遅延を削減するためには、パイプライン処理が適している。図5はIP転送の読み込み(受信)と書き込み(送信)のステージをそれぞれ0と37ステージで行い、書き込みステージにおいて先頭データにTOS(Type Of Service)とおよび送信先ポート情報をTaggingしている様子を示している。枠内の数字はフレーム位置を示す。書き込み時の先頭フィールドに送信先ポート情報を記述することにより、そのあとの工程においてパイプラインハザードが起きなくなる。
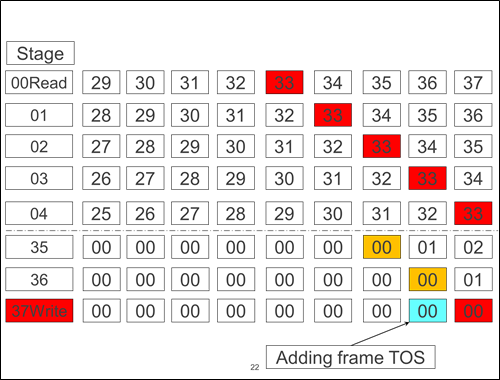
図5: パイプライン処理によるパケット転送
評価
評価は4ポートFPGAボード上に本設計を実装したもので行った(写真1)。

写真1: PCIバス搭載 FPGAボード本体
図6は、計測ツールにより64バイト長のフレームを送信したときの転送遅延を計測表示したものである。
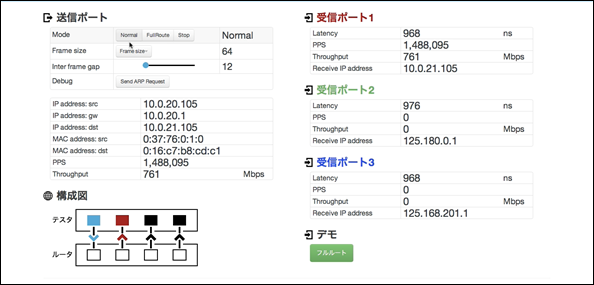
図6: 計測画面
図7に市販のスイッチと本実装(FIBNIC+PC Router IPv4)の比較を示す。
本実装ではフレームサイズにかかわらず1us未満の転送遅延であることが確認できた。
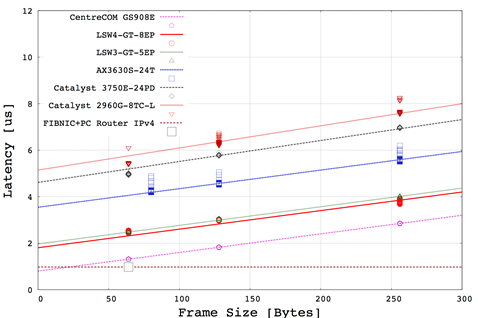
図7: フレームごとの転送遅延
出展・発表 (2012年度)

写真2: ORF2012での展示
まとめと今後の課題
本年度までの研究により、Gigabit Ethernet環境において透過的分散コンピューティングの為の共有メモリ機構の基本部分とそれに対応するためのネットワーク機器を設計・実装することができた。
しかしながらGigabit EtherentはPCI Expressよりも低速であり、大規模なメモリー書き換えがあるとボトルネックが多数発生する。今後は10G Ethernetに対応させることにより、より高い性能を目指す。