研究成果報告書
目次
- 概要
- 背景
- 実験システムの試作
- 期待される効果
- 主な参考文献と発表記録
概要
本研究では, WEBデザイン画像における文字の役割を推定する手法を提案し, そのプロトタイプシステムの開発を行う. 今年度は, 情報抽出に関する論文からWEBページを対象とした研究を中心にサーベイを行い, 既存研究との違いを明らかにした. また, 人がHTMLのマークアップをする際に文字の役割を判断している要素(=特徴量)を明らかにするための実験システムの試作を行った. 春休みを通じて実験を行い, 来年度はその特徴量を用いて研究のプロトタイプシステムの開発に入る予定である.
背景
Linked Open Data Challengeの開催やビッグデータという言葉が広く取り上げられるようになったことが象徴するように, Web上にあるオープンデータを活用する動きが活発になっている. このような動きの中で大量にあるWebページ(HTML)の解析からデータを集めることは有力な手段であり, そのためにはHTMLで正しくマークアップされていることが重要である. しかしWebページは見た目の美しさや読みやすさを重視してデザインされており, デザインが複雑になるにつれて正しいマークアップでHTMLを書くのには時間がかかるため, コーダーの作業量は増加し結果として煩雑なマークアップになってしまうことが少なくない. この問題を解決するために, WebデザインをHTMLでマークアップする作業を効率化することが重要である.
実験システムの試作
システム概要
入力:WebページのURL
出力:文字をすべてダミーテキストに置き換えたデザイン画像
目的
人間は何を元にデザインからマークアップするタグを判断しているのか(つまりどの特徴量があれば機械でもできるのか)仮説を立てるため
課題
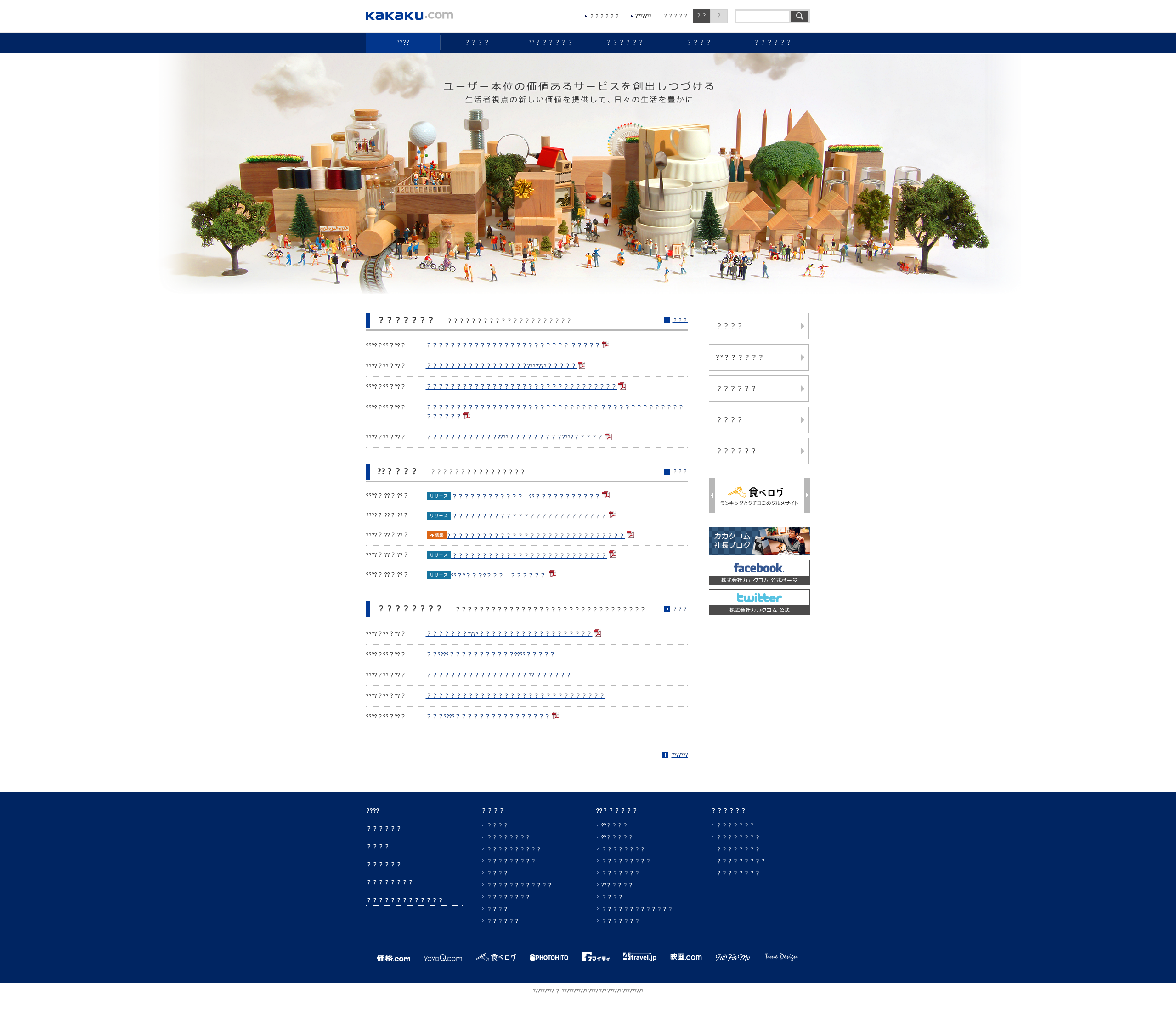
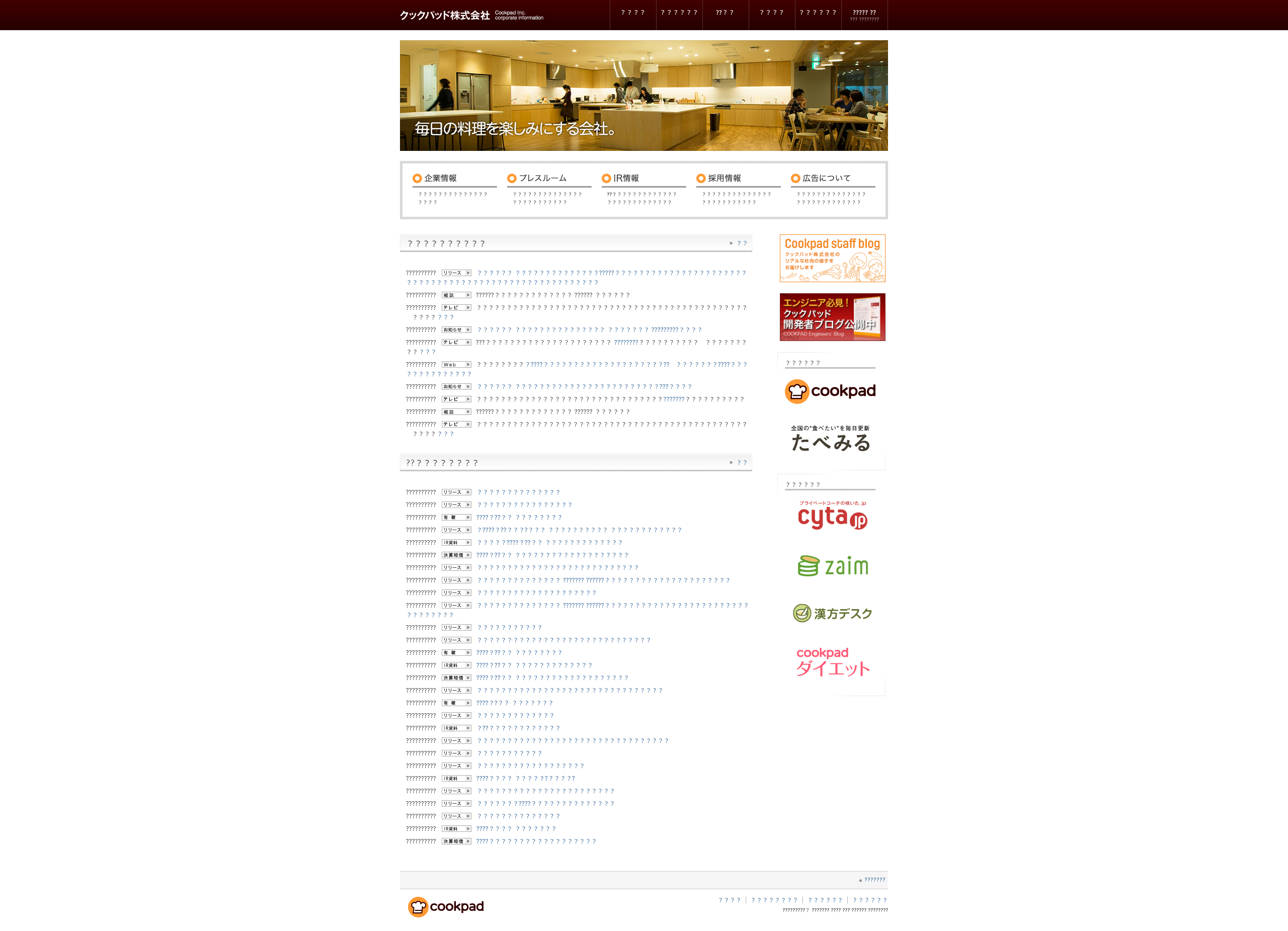
現在は画像内に文字が埋め込まれているとその部分の文字に関しては置換できないが、画像の色やその中の文字の大きさによって見出しタグかどうか判断できてしまうため、画像そのものを置き換えるかどうか判断に迷っている。
とりあえず、画像は置き換えずに(画像に埋め込まれているものは無視)文字の意味を考えずにどこまでタグ付けができるのか仮説を立てたい。
文字置き換え後のサンプル画像
期待される効果
本研究が進むことでWEBエンジニアがフロントエンドのデザインのマークアップに費やしている時間が大きく減少し, よりクリエイティブな仕事に着手できるようになる. 既存の自動コーディングの解決策はデザイナーがデザインする際に規則に従ってネーミングやデザインすることで自動化しようという試みであった. 本研究は既存のWEB制作フローを大きく変え, コーダー・デザイナーの時間・スキルをより創造性を要する人為的な作業に集中させることが可能になる.