| 2.研究手法 |
|
1.使用したデータ 今回の研究には、以下のデータを使用した。理化学研究所のマウス fulll-length cDNAは公開済であるが、農林資源研究所のイネ full-length cDNAは未公開データである。また、M. musculus のmicro-array dataは、選択的スプライシング候補のcDNAについてまとめられたデータベースを理化学研究所から提供されたものを使用した。 | |||||||||||||||||||||||||
| |||||||||||||||||||||||||
|
表1:使用したデータ | |||||||||||||||||||||||||
|
2.完全長cDNA配列とゲノム配列との比較 マウス・イネの完全長cDNAは、以下の図に示される3ステップでゲノム配列へマッピングされる。 | |||||||||||||||||||||||||
| |||||||||||||||||||||||||
|
3.マイクロアレイデータを用いた組織特異的cDNAの特定 我々はこれまでの研究により、マウスの完全長cDNA 21,076本のうち、1,136本のcDNAからなる415グループを選択的スプライシング候補のcDNAクラスターとして特定した。理化学研究所は完全長cDNAを作成するにあたり、マイクロアレイによって組織・発育段階別(49種類)にmRNAの発現量を測定し収集してきた。これまで18,816本のcDNAについて測定されたものがWEB上にて公開されている[14]。マイクロアレイデータは、発現パターンが類似するタンパク質には何らかの関連性があるという名目のもと、多数の遺伝子を発現パターンによって任意の数の遺伝子群に分類し、クラスタリングされた遺伝子がコードするタンパク質の同定に利用されることが多い。我々はこの発現量が表されたマイクロアレイデータを利用し、選択的スプライシングとして推定されたクラスターのうち異なる組織・発育段階にて発現の量が大きく変化するものを同定した。 | |||||||||||||||||||||||||
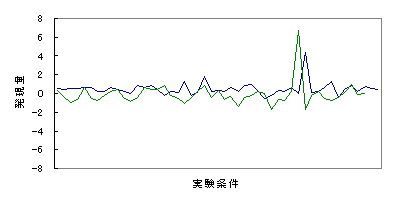
図2:マイクロアレイデータの例 | |||||||||||||||||||||||||
|
同定手法としては、縦軸に発現量、横軸に組織・発育段階(実験条件)をとって各cDNA毎の発現量をグラフ化し、一部分だけ異なる波形をとっているクラスターを抽出した。また、予測されたORF (open reading frame)情報を用い、選択的にスプライスアウトされるエクソンがORF内にあるcDNAについては、エキソン内にタンパク質のモチーフが存在するかどうかをhmmpfam[15]を用いて検索した。 | |||||||||||||||||||||||||
|
4.選択的スプライシングサイト周辺配列の解析
選択的スプライシングの制御配列を探るにあたり、まず公共のデータベースであるGenBankに 'alternative splicing(選択的スプライシング)' の記述がなされているmRNAを抽出し、既知選択的スプライシングmRNAのデータセットを作成した。これらのmRNA配列を上述の方法にてゲノム配列と比較し、エキソン/イントロンの情報を取得した。この情報をもとに各スプライスサイト周辺8bpを抽出し、選択的なスプライスサイト周辺配列と通常のスプライスサイト周辺配列の比較解析を行った。 | |||||||||||||||||||||||||

図3:選択的スプライシングの模式図 |
[TOPへ 1. はじめに 2. 研究手法 3. 結果 4. 考察 5.今後の展望 6. 参考文献 7. 実績 ]