1.分析対象ジャンルの選定
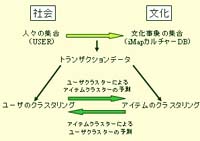
iMapでは社会階層を前提とはせず、「社会」(個人)は、唯一「文化」(趣味)クラスターとの相互参照によってのみ行われなければならない。そのためには、個人の持つ属性(生年・性別・職業・出身地など)はあらかじめ完全に排除し、USERとITEMのみに限定したトランザクションデータを用いる必要がある。
ただしそのトランザクションデータの特性は、ジャンルによってまちまちである。女性限定や若者限定では極めて有用であっても、iMapが目指す産業社会以降の日本社会/文化の全体像を捉える上では適切でないジャンルも数多く含まれる。
今年度の研究目標は、「社会」と「文化」の相互参照システムを開発することにある。よって、まずは特定ジャンルに絞って、そのシステムのモデルを作成することが先決であると考えた。
その、モデルとなりうるジャンルの条件は、大きく以下の4点である。
<1>世代差なく回答されていること
<2>男女差なく回答されていること
<3>ITEM数・USER数ともに豊富であること
<4>序列効果の影響が少ないこと
以下、条件ごとに説明を加える。
<1>世代差なく回答されていること
| サンプリングを行わないならばなおさら、得られたUSER(従来でいうところのサンプル)の属性が偏っていないことが重要である。 具体的にジャンル名を挙げるならば、「ゲーム」や「ビデオアニメ」は若者からの回答が大半を占めるジャンルであり、逆に「自動車」などは青年以上の年配層に支持されるジャンルである。 これらは世代を限定したセグメント分析には向いているが、社会全体の分析には不向きなジャンルであるといえよう。 (右図は「11_ゲーム」) |
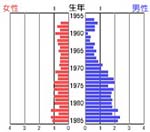 |
<2>男女差なく回答されていること
|
前項同様に、「野球」「サッカー」を中心とするスポーツ全般は男性からの回答率が高く、女性からは低い。 |
 |
<3>ITEM数・USER数ともに豊富であること
従来型社会調査の解析ツールである主成分分析や数量化Ⅲ類では、サンプル数が多く(例えば10,000サンプル)、アイテム数が少ない(例えば50アイテム)データが用いられるケースがほとんどであった。
しかし、それではiMapが理想に掲げる「社会」と「文化」をともにクラスタリングして相互参照させることは難しい。
そのように考えると、トランザクションデータにおいて行列関係にある、ITEMとUSERが、ともに豊富であることが不可欠である。よって、従来型に近い、USER数は多いがITEM数は少ない「流行語」といったジャンル、そして逆にITEM数の割にUSER数が少ない「知識」「芸術」や「政治経済」「社会世相」といったジャンルも、分析対象から除外せねばならないだろう。
(ちなみに、「29_服飾スタイル」ではITEM数163・USER数672とともに少なく、「27_海外旅行」ではITEM数2,613に対してUSER数806とバランスが悪い。)
<4>序列効果の影響が少ないこと
 全質問項目に回答を促す従来型社会調査と違い、iMapが行っているWEB社会調査は、コンビニにおける商品購入に似て欠損値の方が圧倒的に多い。その上、回答される項目も商品の陳列棚のように、WEB表示による序列の影響をあからさまに受けてしまう。
全質問項目に回答を促す従来型社会調査と違い、iMapが行っているWEB社会調査は、コンビニにおける商品購入に似て欠損値の方が圧倒的に多い。その上、回答される項目も商品の陳列棚のように、WEB表示による序列の影響をあからさまに受けてしまう。
iMapのジャンルにも表示における序列があり、「1_邦楽」「2_洋楽」…「35_海外旅行」まで、35ジャンルが“順に”並んでいる。筆頭の「邦楽」は、折り返して表示される場合にも左上に配置され、すべてのUSERが試験的にクリックする傾向にあるジャンルである。また、内部構造的にもSUBGENRE(五十音順)の影響が他ジャンルにも増して強い。
こういったデータクリーニングの難しいノイズの激しいジャンルは、今回のモデルケース作成にはそぐわず、従って排除しなければならない。
(のちに序列効果を排除する手法が開発されるわけであるが、分析を開始する段階では、まだ模索中であった)
以上の4大条件を基に消去法で分析対象ジャンルを絞り込んでいくと、そこには「マンガ」しか残らない。従って本年度のiMap分析は、「マンガ」ジャンルを対象ジャンルに設定して、分析を行うことに決まったのである。