2.レイヤー分割と相関ルール (2001年度春学期)
分析対象ジャンルが決まったところで、次に行ったのが「文化」(趣味)のクラスタリングである。
「社会」(個人)のクラスタリングにはUSERを、「文化」(趣味)のクラスタリングにはITEMをそれぞれ用いるとしたが、前者のUSERにおけるクラスタンリング結果からは、分析の精度を検証することは難しい。
なぜなら、USER1とUSER256とが同一クラスターに含まれる、あるいはハンドルネームによって、ondというUSERとkiichiというUSERが同一クラスターに含まれることが仮にわかっても、その二人を現実世界で知らない分析者側が、その結果を正しいと判断できる根拠はどこにも見当たらないからである。
よって、最初に行わなければならないクラスタリングは、「文化」すなわち、この場合「マンガ」のITEM(漫画家名)においてである。これならば、例えば「藤子・F・不二雄」と「藤子不二雄A」とが同一クラスターに含まれる結果が導き出された際に、「それは正しい」と判断することが可能だからである。
実際の分析のプロセスは、以下の3段階に集約される。
<1>レイヤー区分
<2>マンガMapの作成
<3>相関ルールによるクラスタリング
以下、プロセスごとに詳説する。
<1>レイヤー区分
「マンガ」に含まれるITEM数は894であり、これらすべてのマンガITEMを分析対象としたのでは、分析の完了目処はいつになっても立たない。
我々はマンガ評論を専門的に展開しようとしているのではないし、iMap分析の目指す最終ゴールは「マンガ」分析には限らない。あくまで今回の「マンガ」分析によって、分析モデルを作成することが主題である。としたならば、分析対象ITEMを限定することはやむを得ないだろう。またその方が、ノイズを排した精度の高い分析結果を保証するに違いない。
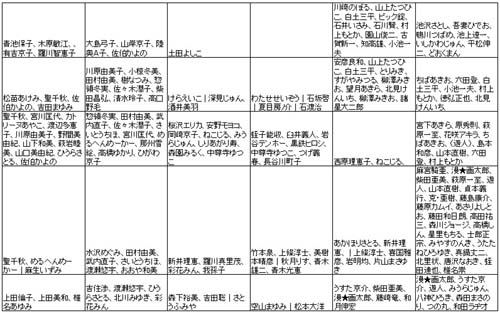
| iMapでは「文化」に対して、高尚・低俗といった階層を想定してはいない。ただし回答結果からは、認知度における階層化現象が見られる。よって、この階層を利用して、一定の範囲内にある上位ITEMを分析対象にする方法を思いついた。 ただし、従来のマンガ分析が行ってきたような、トップ10、細かくてもせいぜいトップ100といった分析では、今日の多様化・細分化に対処することは不可能である。分析の中心に据えたいのは「誰もが知っているわけではないが、特定の人たちから強い支持を得ているITEM」である。それらがレイヤー3に含まれると想定し、それよりわずかに下位ある、「かなりオルタナティブでクラスター化するのが限界ギリギリであるITEM」をレイヤー4に想定した。 この段階では、誰もが知っているレイヤー1から順に、ITEM数はレイヤー1:35、レイヤー2:65、レイヤー3:100、レイヤー4:150とし、これにより計350ITEMが分析対象として選定された。 |
<2>マンガMapの作成
 理想的にはITEM間の位置関係は相対的に決まるとしているが、これではシステムが開発されるまでITEMを図示することができず、分析を進める上で支障を来たすことは明らかである。
理想的にはITEM間の位置関係は相対的に決まるとしているが、これではシステムが開発されるまでITEMを図示することができず、分析を進める上で支障を来たすことは明らかである。
よって便宜的に、ITEMに座標を与えることが必要となってくる。そこで参照したのが「性別」と「生年」である。
この2つは、産業社会ほどの絶対的な規定力は失われたといえるが、それでも依然として強力な規定力をもつ属性である。ことに「マンガ」は、掲載誌や書店の配置等の影響が大きく、この2変数が他ジャンルよりも有効に作用していることは自明である。
「性別」「生年」情報を基に、レイヤーごとにITEMを配置したことによって、視覚的に分析が進めやすくなったことは言うまでもない。
<3>相関ルールによるクラスタリング
これでクラスタリングに入る準備は調った。当時のマイニング知識の制約上、我々は相関ルールを用いるのが最も妥当性が高いと判断した。
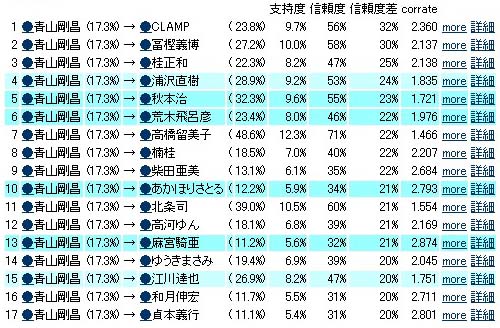
ただし、支持度(認知度=回答数)による影響が大きく、また、ITEM同士の結びつきの強弱という判断を、数値的にどこを基準とすればよいのか、などの問題点が積み残こされた。
クラスタリングに分析者の恣意的な判断を入れてしまっては、従来型の権威者による意味づけと大差がない。春休み以降は、この問題をどうクリアし、論理的で実証的なクラスタリング手法の確立に繋げるかが懸案事項となっていく。
恣意性を介在させつつも、第1回クラスタリング結果は以下のようになった(レイヤー3)。