4.データクリーニング (2001年度秋学期Ⅰ)
SUBGENRE(五十音順)がもたらす「石と池問題」のような序列効果の弊害は、WEB調査が共通して抱える問題であり、「1_邦楽」が分析対象から外れざるを得なかった理由もこれに求められる。その影響がいかに顕著であったかは、以下の相関ルールの結果からも明らかである。
| 3266 | <- | 10100 | (4.5% | 61.8%) | ウルフルズ | 宇多田ヒカル | ||
| 10100 | <- | 3266 | (4.5% | 73.7%) | 宇多田ヒカル | ウルフルズ | ||
| 10100 | <- | 2124 | (3.3% | 68.4%) | 宇多田ヒカル | Wink | ||
| 10100 | <- | 3211 | (3.0% | 66.3%) | 宇多田ヒカル | うしろゆびさされ組 | ||
| 9927 | <- | 9934 | (3.8% | 64.9%) | 安室奈美恵 | 安全地帯 | ||
| 9927 | <- | 9950 | (3.4% | 62.3%) | 安室奈美恵 | 杏里 | ||
| 9927 | <- | 2390 | (3.2% | 62.7%) | 安室奈美恵 | あみん | ||
| 9927 | <- | 2563 | (3.3% | 65.4%) | 安室奈美恵 | アン・ルイス | ||
| 11664 | <- | 13294 | (3.2% | 66.5%) | 今井美樹 | 石井竜也 | ||
| 12503 | <- | 12478 | (3.2% | 64.0%) | 小泉今日子 | 小室哲哉 | ||
| 12503 | <- | 11618 | (3.1% | 68.6%) | 小泉今日子 | 国生さゆり | ||
| 4838 | <- | 2184 | (3.3% | 65.9%) | サザンオールスターズ | ZARD | ||
| 3711 | <- | 3724 | (3.5% | 64.5%) | おニャン子クラブ | オフコース | ||
| 10048 | <- | 2943 | (3.5% | 67.6%) | 井上陽水 | イルカ | ||
| 10048 | <- | 10071 | (3.0% | 68.0%) | 井上陽水 | 一世風靡SEPIA | ||
| 10048 | <- | 10050 | (3.2% | 73.1%) | 井上陽水 | 井上陽水奥田民生 | ||
| 10048 | <- | 10084 | (3.1% | 71.3%) | 井上陽水 | 稲垣潤一 | ||
| 11158 | <- | 10904 | (3.8% | 65.7%) | 桑田佳祐 | 久保田利伸 | ||
| 1087 | <- | 1089 | (3.6% | 73.0%) | Kinki | Kids | Kiroro | |
| 3266 | <- | 2124 | (3.2% | 67.0%) | ウルフルズ | Wink | ||
| 15490 | <- | 12552 | (3.2% | 68.8%) | 米米CLUB | 小柳ゆき | ||
| 1769 | <- | 1805 | (3.3% | 68.6%) | SMAP | SPEED |
この問題を解決しない限り、いかに精度の高いクラスタリング手法が確立されたとしても、現状に即した結果は得られない。では、いかにして解決していくか。
幸運にもiMapには、序列効果をそのまま数値化している変数が存在する。それは「SUBGENRE_ID」である。
1「あ」、2「い」、…、44「わ」までの44個のSUBGENRE_IDを参考にすることで、何かしら法則性が導き出せるに違いない。そこでまず、以下2つの解決策を提案した。
<1>SUBGENRE_ID平均の低いUSERを削除する
下のグラフにあるように、USERごとのSUBGENRE_IDの平均をとって分布させると1.0~4.5付近の偏りを除いては概ね正規分布に近いかたちで分布していることがわかる。よって、SUBGENRE_ID平均が4.5未満のUSERを一律削除すれば、あ行の強いバイアスを軽減できるに違いない。
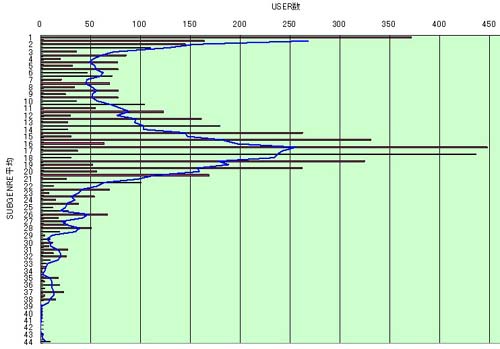
この方法には、多くのUSERを削除しなくてもすむ利点がある反面、明確な基準に乏しく(なぜ4.5未満なのか?)、序列の初めの部分に関してのみ、逆に強いマイナスのバイアスをかけているのではないか、という欠点が指摘できる。
<2>中央値を基準として、それよりも回答数の少ないUSERを削除する
マイニングデータのクリーニングにおいて経験的に用いられてきたのは、回答数の少ないUSERを削除するという方法である。しかし、少ないとする基準をどこに設定するのかは判断が難しい。
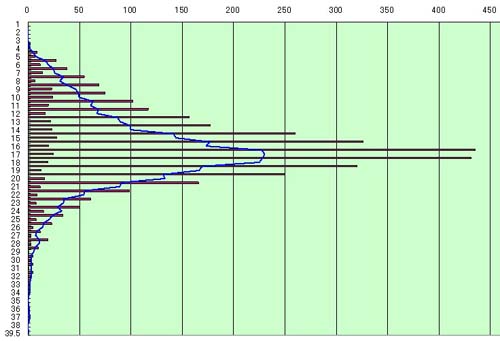
そこでまず、回答個数ごとのSUBGENRE_IDの標準偏差を調べてみた。下図に示すように、10前後で安定していることがわかる。そしてこの値は、「マンガ」に回答したUSERの回答数を並べた際の中央値(11)に極めて近い。
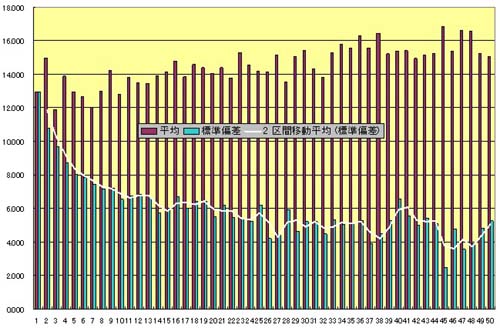
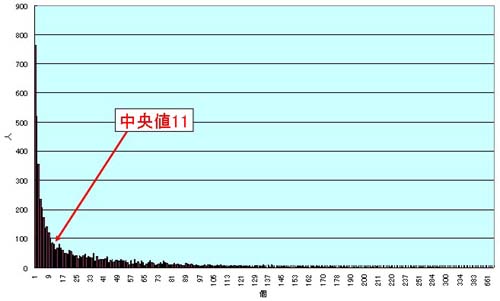
この方法は、中央値という明確な基準がある点では論理的だが、半数近いUSERを削除しなければならないことから、豊富なITEM数とUSER数を要件とする本分析の趣旨にそぐわないとも指摘できる。
<3>SUBGENRE_ID標準偏差の信頼区間を利用する
<2>において、なぜ回答数の少ないUSERを削除するのか。その理由について考えてみた。
iMapのITEM回答数の分布は、上図のように、USER数と反比例の関係にある。多くのWEB調査についてもこの分布が共通するからこそ、少ない回答者を削除することでノイズを防げるのである。ではノイズとは何か?
ノイズとは分散(その平方根が標準偏差)が、標準的なものに比べて、小さすぎたり大きすぎたりすることを意味している。その小ささこそ、まさに<1>における、「あ」や「い」しか答えないUSERの存在である。
ならば、SUBGENRE_IDの標準偏差自体を分布させ、小さすぎるものと大きすぎるものを削除すれば解決できるに違いない。そこで、SUBGENRE_IDの標準偏差分布を調べたところ、下図のように0(1つのSUBGENREにしか回答していない)のUSERが全体の1/4近い11,00人にものぼっていた。
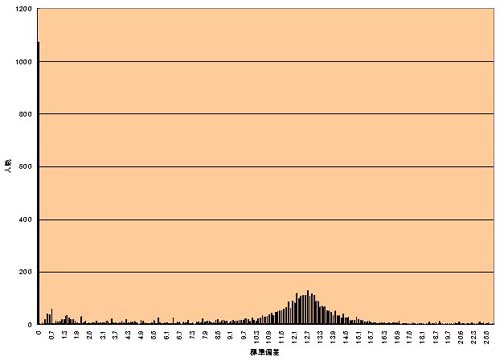
当然これら(標準偏差が0)のUSERは削除対象である。該当するUSERのデータを除いて再度分布を描いてみると、下図のように、正規分布といっても差し支えない分布が登場する。
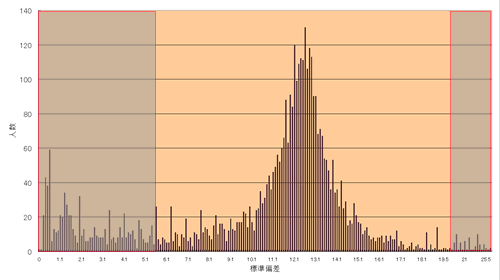
よってこの分布を正規分布と仮定し、統計学の信頼区間を当てはめれば、そこから外れる棄却域のデータを削除できる。ただし、母集団分布が明らかでないから、ここでは、平均と分散を次のように設定しなければならない。
平均 … 小数点以下第2位を四捨五入した場合の最頻値
分散 … 標準偏差が0のUSERを除いたデータの分散
確率密度関数から、 この分布の95%信頼区間は 「5.529~19.871」と求められる。従って、棄却域に落ちる5.528以下と19.872以上のUSERデータを削除すればよい。
最後に精度を確認してみよう。まずは、SUBGENRE_IDの平均分布である。
冒頭のグラフと比較すると、データがいかにクリーニングされているかがおわかりいただけるだろう。
確かに「あ」や「い」しか答えていないUSERは一律削除されているが、これは「あ行」に限ったことではなく、他のSUBGENREにおいても平等になされているのであるから、<1>に比べ統計的な根拠に優れている。なおかつデータの損失も<2>と比べて少なくてすむ。
表の対比によって、未処理の際のランキングと比較してみた結果が以下の表である。
「あ行」のITEMが妥当な位置に収まっている。特に、1位「あだち充」と2位「藤子・F・不二雄」の差が、478からわずか63に激減している点は大きな成果である。
| 未処理データのランキング | クリーニング後のランキング | |||
|
順位
|
ITEM名
|
USER数
|
ITEM名
|
USER数
|
|
1
|
あだち充 |
2162
|
あだち充 |
1693
|
|
2
|
藤子・F・不二雄 |
1684
|
藤子・F・不二雄 |
1630
|
|
3
|
鳥山明 |
1636
|
鳥山明 |
1584
|
|
4
|
一条ゆかり |
1581
|
高橋留美子 |
1400
|
|
5
|
いがらしゆみこ |
1456
|
手塚治虫 |
1350
|
|
6
|
高橋留美子 |
1441
|
一条ゆかり |
1336
|
|
7
|
さくらももこ |
1430
|
さくらももこ |
1327
|
|
8
|
手塚治虫 |
1384
|
いがらしゆみこ |
1198
|
|
9
|
秋本治 |
1199
|
藤子不二雄A |
1153
|
|
10
|
藤子不二雄A |
1188
|
松本零士 |
1127
|
|
11
|
松本零士 |
1154
|
北条司 |
1124
|
|
12
|
北条司 |
1152
|
モンキー・パンチ |
978
|
|
13
|
石ノ森章太郎 |
1136
|
石ノ森章太郎 |
951
|
|
14
|
あさぎり夕 |
1049
|
秋本治 |
931
|
|
15
|
赤塚不二夫 |
1038
|
美内すずえ |
879
|
|
16
|
楳図かずお |
1000
|
ちばてつや |
856
|
|
17
|
モンキー・パンチ |
995
|
あさぎり夕 |
851
|
|
18
|
浦沢直樹 |
982
|
楳図かずお |
848
|
|
19
|
江口寿史 |
952
|
浦沢直樹 |
832
|
|
20
|
江川達也 |
926
|
赤塚不二夫 |
825
|
よって現状では、序列効果を排除するデータクリーニング方法として、上記の方法が最適である、と結論づけることができる。