Method2.データクリーニング
2-1. データクリーニングの必要性
iMapではアイテムの選定作業を行っていない。想定しうるすべてのアイテムを調査項目としてセットした。その理由については、次の呉智英の文章からの引用によって理解されたい。
「厖大なマンガ出版物が刊行されている以上、私が不得意なものも多い。少女マンガについては詳しいほうではないし、幼年マンガについては全く不案内である」 (『現代マンガの全体像』双葉社、1997、p.12)
このように高名なマンガ評論家であっても、すべてのマンガへのレビューが叶わぬほどに、作品が乱発されている現状が今日のサブカルチャー化を象徴している。付け加えるならメディア・コミュニケーションの構造分析に主眼を置く本研究では、そもそもマンガ家などのアイテムに優劣をつけない。たとえ評論家に酷評されるような作品であろうとも、そこに一定のファンが存在する限り、その作品は分析にとって価値あるものと考える。これが絞り込むことなく20万件近い文化事象をデータベース化している根拠である。
他方のユーザに関しても、社会調査の前提となるサンプリングを行っていない。だが、こちらは無視できない弊害を伴う。ディジタル・ディバイドを除いて一番の問題となるのはノイズの多さであろう。このノイズを解決しない限り、たとえ膨大なデータを獲得できたとしても実証分析には耐えられない。POSデータの解析をはじめ、データマイニングが適用されるような大規模データを扱うケースでは、いかに入念にデータクリーニングを行うかが成功を大きく左右するといわれており、以下のような試算もある。
「経験を積んだアプリケーション・コンサルタントは、開発期間の50%から75%はそもそもニューラル・ネットワーク入力前のデータ操作に費やされていると推測している。であるから、強力なデータアクセス・ツール、データクレンジング、及び前処理操作法が効果的なデータマイニングにとって本質的である」 (ジョゼフ・P・ビーガス(Joseph P. Bigus)、社会調査研究所・日本IBM(訳)『ニューラルネットワークによるデータマイニング』日経BP、1997、p.85)
2-2. データクリーニング事例
iMapによって得られたデータの不安定性の問題は、「序列効果」と「見せかけの支持度 」の2点に集約される。
|
「序列効果」とはアイテムの表示順に伴うバイアスを意味する。全回答を強要しないiMapでは、ユーザがすべてのアイテムに目を通すことは期待できない。その場合、当然のように回答は特定箇所に偏る。iMapは50音順にアイテムを序列化しているから、一般的な回答手順を想定すると、「わ」や「ら」で始まるアイテムよりも、50音の冒頭である「あいう…」で始まるアイテムに回答が集中してしまう。このような序列効果を、アイテムの頭文字について、「あ」を1、「い」を2…として定量化し、ユーザごとに回答アイテムの頭文字標準偏差を抽出し、誤差の許容範囲を超えるユーザを削除することで解決した(右上図は例としての「マンガ」回答標準偏差の95%信頼区間)。 |
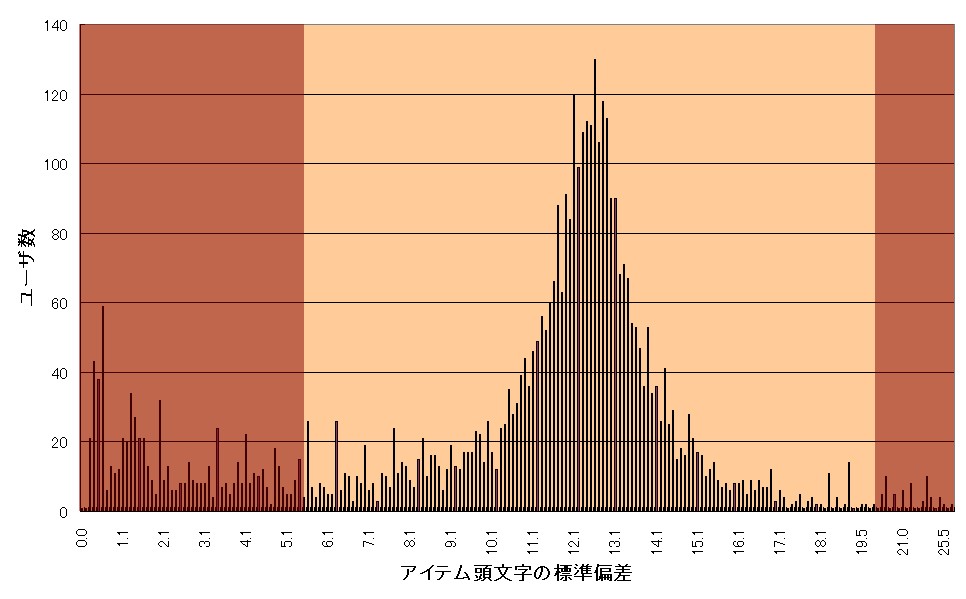 |
|
「見せかけの支持度」とは、後述のレイヤー分割とも関連する問題である。10代・20代・30代…といった世代間バランスを考慮した層化抽出を行わないiMapでは、母体となるユーザ比率(右下図)から回答数が強い影響を受ける。 この問題に対しては、生年ごとにクリックした人の割合である「支持度」を算出し、その加重平均である「平均支持度」を採用することで「マンガ」や「ゲーム」については解決を図った。「服飾ブランド」については、対象を女性に限定したところ、20歳から35歳まで(2003年現在)のユーザ構成比が、総務省人口統計に近似したため、これを採用した。 |
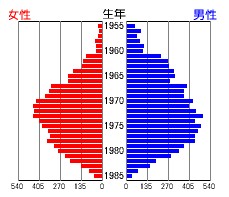 |
「序列効果」と「見せかけの支持度」の2つの問題解決によって、データが文化の現状に近づいたことは、ジャンル「マンガ」の各段階におけるランキングトップ20の推移からも理解されよう(下表)。
|
順位
|
未処理データ
|
序列効果軽減後
|
世代間補正後
|
|||
|
ITEM名
|
USER数
|
ITEM名
|
USER数
|
ITEM名
|
平均支持度
|
|
|
1
|
あだち充 |
2,162
|
あだち充 |
1,693
|
藤子・F・不二雄 |
39.01%
|
|
2
|
藤子・F・不二雄 |
1,684
|
藤子・F・不二雄 |
1,630
|
あだち充 |
37.10%
|
|
3
|
鳥山明 |
1,636
|
鳥山明 |
1,584
|
鳥山明 |
35.56%
|
|
4
|
一条ゆかり |
1,581
|
高橋留美子 |
1,400
|
手塚治虫 |
34.29%
|
|
5
|
いがらしゆみこ |
1,456
|
手塚治虫 |
1,350
|
高橋留美子 |
31.53%
|
|
6
|
高橋留美子 |
1,441
|
一条ゆかり |
1,336
|
さくらももこ |
30.64%
|
|
7
|
さくらももこ |
1,430
|
さくらももこ |
1,327
|
一条ゆかり |
30.23%
|
|
8
|
手塚治虫 |
1,384
|
いがらしゆみこ |
1,198
|
松本零士 |
28.65%
|
|
9
|
秋本治 |
1,199
|
藤子不二雄A |
1,153
|
藤子不二雄A |
27.74%
|
|
10
|
藤子不二雄A |
1,188
|
松本零士 |
1,127
|
いがらしゆみこ |
26.39%
|
|
11
|
松本零士 |
1,154
|
北条司 |
1,124
|
石ノ森章太郎 |
25.01%
|
|
12
|
北条司 |
1,152
|
モンキー・パンチ |
978
|
赤塚不二夫 |
24.20%
|
|
13
|
石ノ森章太郎 |
1,136
|
石ノ森章太郎 |
951
|
モンキー・パンチ |
23.96%
|
|
14
|
あさぎり夕 |
1,049
|
秋本治 |
931
|
ちばてつや |
23.43%
|
|
15
|
赤塚不二夫 |
1,038
|
美内すずえ |
879
|
楳図かずお |
23.19%
|
|
16
|
楳図かずお |
1,000
|
ちばてつや |
856
|
水島新司 |
22.85%
|
|
17
|
モンキー・パンチ |
995
|
あさぎり夕 |
851
|
北条司 |
22.82%
|
|
18
|
浦沢直樹 |
982
|
楳図かずお |
848
|
秋本治 |
21.89%
|
|
19
|
江口寿史 |
952
|
浦沢直樹 |
832
|
美内すずえ |
20.94%
|
|
20
|
江川達也 |
926
|
赤塚不二夫 |
825
|
小林よしのり |
20.32%
|
序列効果を処理することで「あ行」のマンガ家がより妥当な順位に座り(水色)、平均支持度を採用することにより、広い世代から平均的に高い支持を集めるマンガ家が上位へと躍り出る(黄色)。このような補正を行うことで、インターネット調査データは、初めて実証分析に耐えうる信頼性を獲得するのである。