Method3.レイヤー分割
3-1. レイヤー分割の必要性
iMap分析では、アイテムに優劣をつけない。そのため、選定作業を行わず、想定しうるすべてのアイテムをデータベース化している点は先に述べた通りである。だが"認知度"に基づく有名性に、一定の序列構造が存在しているのも確かである。アソシエーション・ルールやクラスタリングを実行するにあたっては、認知度が同等なアイテム同士に階層区分することが望まれる。なぜなら、アイテムの認知度を揃えて比較しない限り、有名なアイテム同士、無名なアイテム同士が単純に結合してしまい、有益な知見を得る妨げとなるからである。
※この理由については、集合論におけるベン図を想定すればわかりやすい。例として「ゲーム」における『ファイナルファンタジー』『信長の野望』『維新の嵐』の3アイテムを挙げよう。ユーザ層の近似性を考えれば、同一メーカー(光栄/コーエー)が手がける同一ジャンル(歴史シミュレーション)の『信長の野望』と『維新の嵐』の関係性が近いように思える。しかしマイニング結果では、『ファイナルファンタジー』と『信長の野望』の関係性が強くなる可能性が高い。この原因は集合の積にある。互いに大きなパイ(認知率)を持つ『ファイナルファンタジー』と『信長の野望』は、ユーザの重複率が大きくなるからである。つまりこの場合の解析結果は、文化的な近似性ではなく、「有名なゲームタイトル同士」という関係性を示すことになる。
また階層区分は、細分化の問題意識とも直結する。より上の層ほど「メインカルチャー」的傾向が強く、より下のレイヤーほど「サブカルチャー」的傾向が強いと判断できるためだ。後者を前者と比較することにより「サブカルチャー化」のメカニズムが明らかとなるに違いない。
3-2. レイヤー分割事例
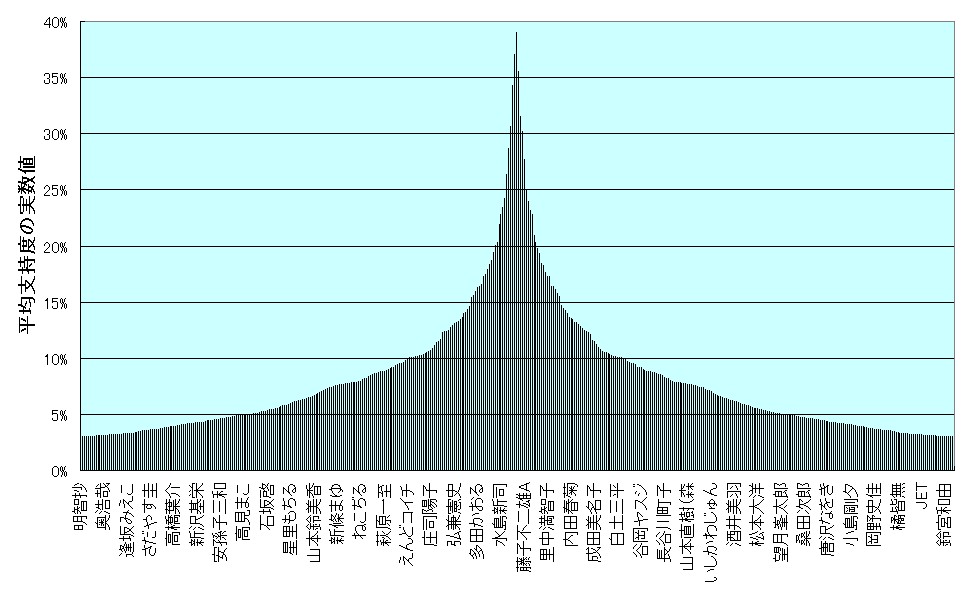
レイヤー分割を定量的に行う手法としては、頂点に位置するアイテムの認知度(回答ユーザ数)を基に等分する方法がまず考えられる。ただし、その認知度については(1)実数のほかに、(2)対数、(3)平方根、(4)面積比率 を利用したものが考えられる。
 |
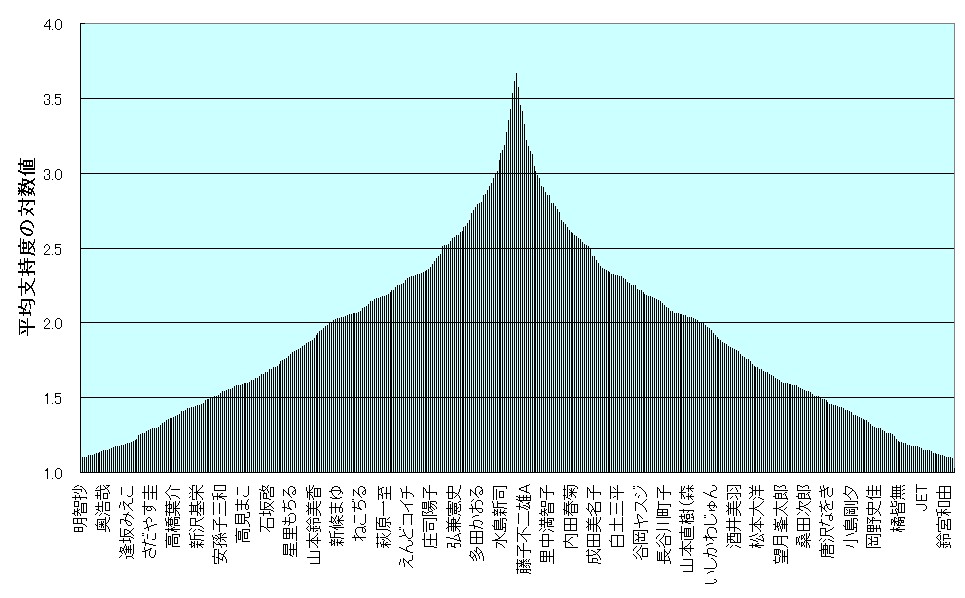 |
実数のままでは、序列関係が指数関数的な形状となり、等間隔でレイヤー分割を行うと、裾野部分に含まれるアイテム数が圧倒的に多くなってしまう(上左図)。そのため、対数化を図り、ピラミッド型に近似させるのである(上右図)。
この手法が適合的だったのは、ジャンル「マンガ」「ゲーム」であった。ともに全レイヤー数を6として分割を行い、「マンガ」では上位4レイヤーを、「ゲーム」では上位5レイヤーをそれぞれ分析対象とした。ボトムレイヤーを対象としなかった理由は、データクリーニング後とはいえ、下位のレイヤーほどノイズが不可避なためである。
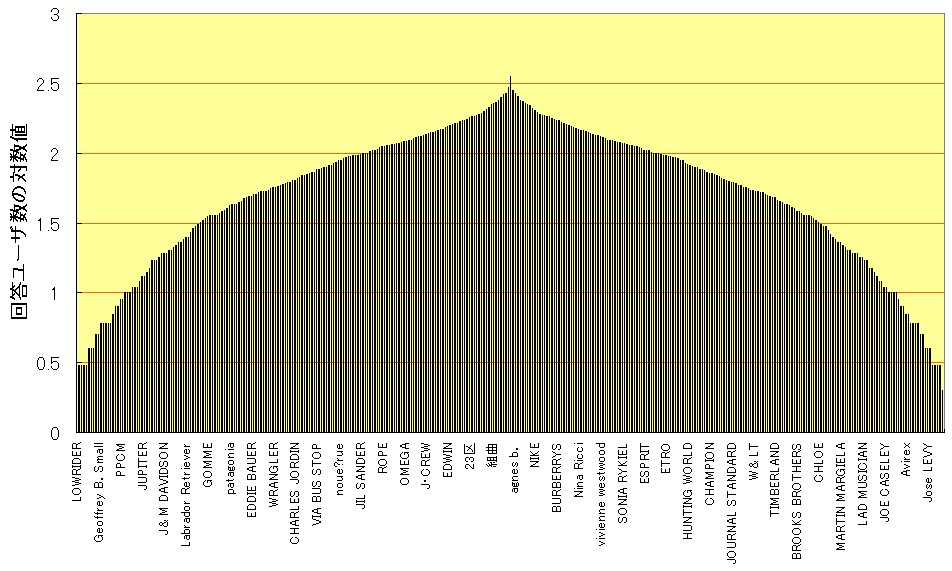
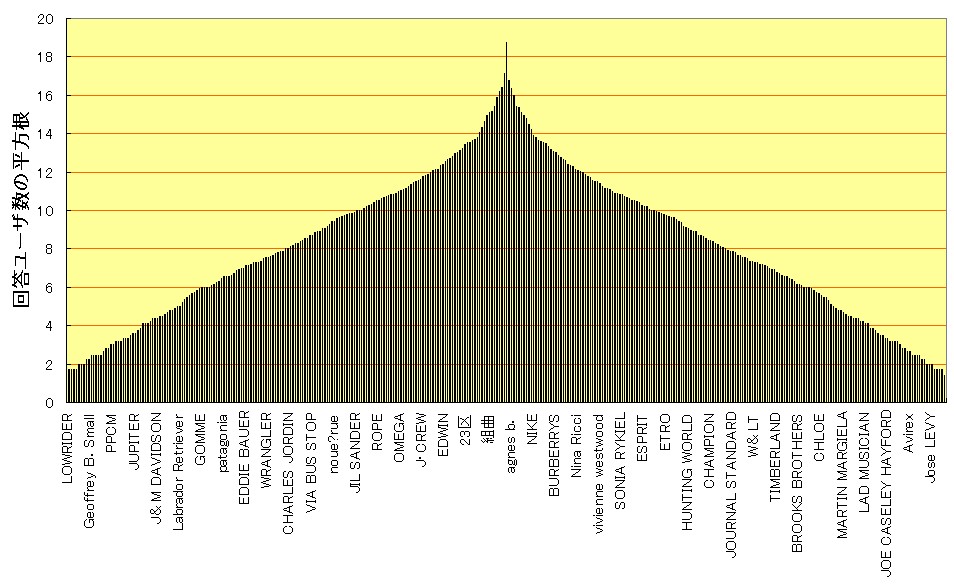
しかしながら、「服飾ブランド」にはこのモデルが適用できなかった。対数化を行ってもピラミッド型には近似せずドーム型となる(下左図)。そこで平方根化を試みたところ、「マンガ」や「ゲーム」において対数化を行った場合と同様の分布が得られた(下右図)。よってジャンル「服飾ブランド」においては、平方根化を利用したレイヤー分割を行った。レイヤー数は6、分析対象は上位4レイヤーである。
 |
 |
※「マンガ」「ゲーム」「服飾ブランド」それぞれの各レイヤー内のアイテム数は、「マンガ」でL1=18、L2=67、L3=156、L4=208、L5=243、L6=202(計894アイテム)、「ゲーム」でL1=9、L2=54、L3=128、L4=202、L5=210、L6=360(計963アイテム)、「服飾ブランド」でL1=8、L2=32、L3=75、L4=93、L5=150、L6=120(計478アイテム)であり、分析対象アイテム数は「マンガ」449、「ゲーム」603、「服飾ブランド」208であった。